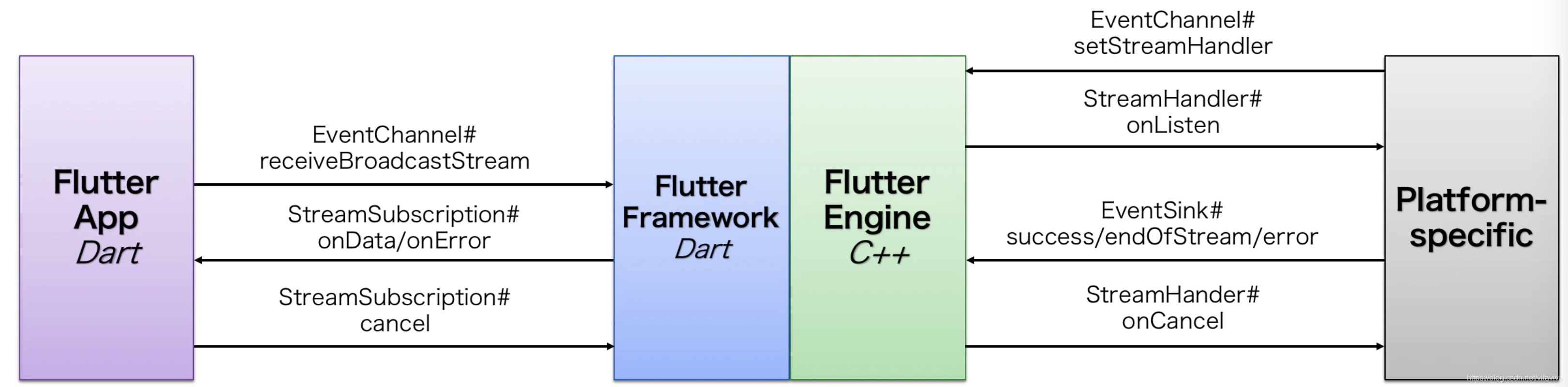
github地址:[感知设备移动数据](https://github.com/EmyWong/PersonalUITech/tree/master/CMAttitudeDemo)
前言
上一篇我和大家一起学习了CMMotionManager获取加速度数据、陀螺仪数据、磁场数据的方式。
今天我们一起学习感知设备移动数据,与上述方式完全相同。
程序也可通过如下两种方式来感知设备移动数据:
> 使用基于代码块的方式获取设备移动数据。
> 使用周期性主动请求的方式获取设备移动数据。
正文
获取设备移动数据时,CMMotionManager将会返回一个CMDeviceMotion对象,该对象包含如下属性:
> attitude:该属性返回该设备的方位信息。该属性的返回值是一个CMAttitude类型的对象,该对象包含roll、pitch、yaw3个欧拉角的值。
欧拉角:用来确定定点转动刚体位置的3个一组独立角参量,由章动角θ、旋进角(即进动角)ψ和自转角j组成,为欧拉首先提出而得名。
不了解欧拉角的同学可以去百度一下。
> rotationRate:该属性返回原始的陀螺仪信息,该属性值为CMRotationRate结构体变量。基本等同于前面介绍的陀螺仪数据。
> gravity:该属性返回地球重力对该设备在X、Y、Z轴上施加的重力加速度。
> userAcceleration:该属性返回用户外力对该设备在X、Y、Z轴上施加的重力加速度。
> magneticField:该属性返回校准后的磁场信息。该属性值是一个CMCalibratedMagneticField结构体变量。CMCalibratedMagneticField类型的变量包括field和accuracy两个字段,其中field代表X、YZ、轴上的磁场强度,accuracy则代表磁场强度的精度。
因为CMAttitude类型的变量用于表示该设备的控件方位。其中roll、pitch、yaw这3个角度的意义如下。
> yaw角度:表示手机顶部转过的夹角。当手机绕着Z轴旋转时,该角度值发生改变。
例如,当该角度为0时,表明手机并未发生旋转,该角度为π/2时,代表手机逆时针转过90°。
> pitch角度:表示手机顶部或尾部翘起的角度。当手机绕着X轴倾斜时,该角度值发生变化。该角度的取值范围是-π~π。
假设将手机屏幕朝上水平放在桌子上,如果桌子是完全水平的。该角度应该是0。
假如从手机顶部开始抬起。直到将手机沿X轴旋转180°(屏幕向下水平放在桌面上),在这个旋转过程中,该角度值会从0变化到π。也就是说,从手机顶部抬起时,该角度值会逐渐增大,直到等于π。
如果从手机底部开始抬起,直到将手机沿X轴旋转180°(屏幕向下水平放在桌面上),该角度值会从0变化到-π。也就是说,从手机底部抬起时,该角度值会逐渐减小,直到等于-π。
> roll角度:表示手机左侧或右侧翘起的角度。当手机绕着Y轴倾斜时,该角度值发生变化。该角度的取值范围在-π/2~π/2。
假设将手机屏幕朝上水平放在桌面上,如果桌面是完全水平的,该角度值应为0。
假如将手机左侧逐渐抬起,直到将手机沿Y轴旋转90°(手机与桌面垂直),在这个旋转过程中,该角度值会从0变化到π/2。也就是说,从手机左侧抬起时,该角度值会逐渐增大,直到等于π/2。
如果从手机右侧开始抬起,直到将手机沿Y轴旋转90°(手机与桌面垂直),该角度值会从0变化到-π/2。也就是说,从手机左侧抬起时,该角度值会逐渐减少,直到等于-π/2。
代码
主要的属性我已介绍完毕,下面我们开始实战演练。
#import "ViewController.h"
#import <CoreMotion/CoreMotion.h>
@interface ViewController ()
{
NSTimer *updateTimer;
}
@property (strong, nonatomic) CMMotionManager *motionManager;
@property (weak, nonatomic) IBOutlet UILabel *showField;
@end
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
// Do any additional setup after loading the view, typically from a nib.
//创建CMMotionManager对象
self.motionManager = [[CMMotionManager alloc] init];
//如果可以获取设备的动作信息
if (self.motionManager.deviceMotionAvailable) {
//开始更新设备的动作信息
[self.motionManager startDeviceMotionUpdates];
} else {
NSLog(@"该设备的deviceMotion不可用");
}
}
- (void)viewWillAppear:(BOOL)animated {
[super viewWillAppear:animated];
//使用定时器周期性获取设备移动信息
updateTimer = [NSTimer scheduledTimerWithTimeInterval:0.1 target:self selector:@selector(updateDisplay) userInfo:nil repeats:YES];
[updateTimer fire];
}
- (void)updateDisplay {
if (self.motionManager.deviceMotionAvailable) {
//获取设备移动信息
CMDeviceMotion *deviceMotion = self.motionManager.deviceMotion;
NSMutableString *str = [NSMutableString stringWithFormat:@"devuceMotion信息为:\n"];
[str appendString:@"---attitude信息---\n"];
[str appendFormat:@"attitude的yaw:%+.2f\n",deviceMotion.attitude.yaw];
[str appendFormat:@"attitude的pitch:%+.2f\n",deviceMotion.attitude.pitch];
[str appendFormat:@"attitude的roll:%+.2f\n",deviceMotion.attitude.roll];
[str appendFormat:@"---rotationRate信息---\n"];
[str appendFormat:@"rotationRate的X:%+.2f\n",deviceMotion.rotationRate.x];
[str appendFormat:@"rotationRate的Y:%+.2f\n",deviceMotion.rotationRate.y];
[str appendFormat:@"rotationRate的Z:%+.2f\n",deviceMotion.rotationRate.z];
[str appendFormat:@"---gravity信息---\n"];
[str appendFormat:@"gravity的X:%+.2f\n",deviceMotion.gravity.x];
[str appendFormat:@"gravity的Y:%+.2f\n",deviceMotion.gravity.y];
[str appendFormat:@"gravity的Z:%+.2f\n",deviceMotion.gravity.z];
[str appendString:@"---magneticField信息---\n"];
[str appendFormat:@"magneticField的X:%+.2f\n",deviceMotion.magneticField.field.x];
[str appendFormat:@"magneticField的Y:%+.2f\n",deviceMotion.magneticField.field.y];
[str appendFormat:@"magneticField的Z:%+.2f\n",deviceMotion.magneticField.field.z];
self.showField.text = str;
}
}
- (void)didReceiveMemoryWarning {
[super didReceiveMemoryWarning];
// Dispose of any resources that can be recreated.
}
@end
运行效果:
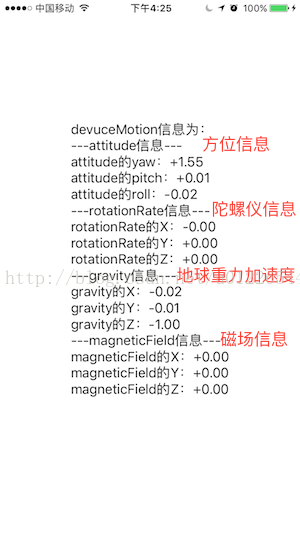
很简单,大家快动手试一试吧~
Flutter 压缩图像的最佳方式
引言
作为开发者的我们,经常会做一些上传图片和和保存图片啦的功能,但是由于一些图片非常大,我们在上传或者保存的时候会占用大量的网络资源和本地资源,那么我们需要做的就是对图片进行压缩。
昨天在写
最新Flutter 微信分享功能实现【Flutter专题23】mp.weixin.qq.com/s/PGpgau6mJLAbfKMVYqTuOg
的时候用到一个知识点,就是图片压缩
当时我用了flutter_image_compress
可能大家都知道Dart 已经有图片压缩库了。为什么要使用原生?
还不是因为他的效率问题,
所以今天就和大家来说一说它的具体用法吧。
1.flutter_image_compress
安装
dependencies:
flutter_image_compress: ^1.0.0-nullsafety
使用的地方导入
import 'package:flutter_image_compress/flutter_image_compress.dart';
/// 图片压缩 File -> Uint8List
Future<Uint8List> testCompressFile(File file) async {
var result = await FlutterImageCompress.compressWithFile(
file.absolute.path,
minWidth: 2300,
minHeight: 1500,
quality: 94,
rotate: 90,
);
print(file.lengthSync());
print(result.length);
return result;
}
/// 图片压缩 File -> File
Future<File> testCompressAndGetFile(File file, String targetPath) async {
var result = await FlutterImageCompress.compressAndGetFile(
file.absolute.path, targetPath,
quality: 88,
rotate: 180,
);
print(file.lengthSync());
print(result.lengthSync());
return result;
}
/// 图片压缩 Asset -> Uint8List
Future<Uint8List> testCompressAsset(String assetName) async {
var list = await FlutterImageCompress.compressAssetImage(
assetName,
minHeight: 1920,
minWidth: 1080,
quality: 96,
rotate: 180,
);
return list;
}
/// 图片压缩 Uint8List -> Uint8List
Future<Uint8List> testComporessList(Uint8List list) async {
var result = await FlutterImageCompress.compressWithList(
list,
minHeight: 1920,
minWidth: 1080,
quality: 96,
rotate: 135,
);
print(list.length);
print(result.length);
return result;
}
还有另外两种方式
2.使用 image_picker 包的 imageQuality 参数
3.使用 flutter_native_image 包
安装
flutter_native_image: ^0.0.6
文档地址
https://pub.flutter-io.cn/packages/flutter_native_image
用法
Future<File> compressFile(File file) async{
File compressedFile = await FlutterNativeImage.compressImage(file.path,
quality: 5,);
return compressedFile;
}
关于如何计算所选文件的图像大小的吗?
您可以以字节为单位获取文件长度,并以千字节或兆字节等计算。
像这样:file.readAsBytesSync().lengthInBytes -> 文件大小以字节为单位的文件大小
(file.readAsBytesSync().lengthInBytes) / 1024 -> 文件大小以千字节为单位的文件大小
(file.readAsBytesSync().lengthInBytes) / 1024 / 1024 -> 文件大小以兆字节为单位
总结
今天的文章介绍了图片压缩的三种用法,分别对应三个不同的库,大家可以去实践,来对比一下那个库的性能更好。
好的,我是坚果,
如何在 Flutter 中创建自定义图标【Flutter专题22】mp.weixin.qq.com/s/1h19t1EAaGTmrFI8gaDLWA
有更多精彩内容,期待你的发现.
Combine之SwiftUI中的状态管理
大家应该都知道SwiftUI的设计理念是Data flow, 也就是View是由数据驱动的,我们把View依赖的这些数据称之为状态,因此,SwiftUI中的数据管理就是状态管理。
常见的状态管理由以下几个:
[AppStorage](https://link.zhihu.com/?target=https%3A//developer.apple.com/documentation/swiftui/appstorage)[Binding](https://link.zhihu.com/?target=https%3A//developer.apple.com/documentation/swiftui/binding)[Environment](https://link.zhihu.com/?target=https%3A//developer.apple.com/documentation/swiftui/environment)[EnvironmentObject](https://link.zhihu.com/?target=https%3A//developer.apple.com/documentation/swiftui/environmentobject)[FetchRequest](https://link.zhihu.com/?target=https%3A//developer.apple.com/documentation/swiftui/fetchrequest)[ObservedObject](https://link.zhihu.com/?target=https%3A//developer.apple.com/documentation/swiftui/observedobject)[State](https://link.zhihu.com/?target=https%3A//developer.apple.com/documentation/swiftui/state)[StateObject](https://link.zhihu.com/?target=https%3A//developer.apple.com/documentation/swiftui/stateobject)
在开发中,他们的用法可以用下边这个图概括:
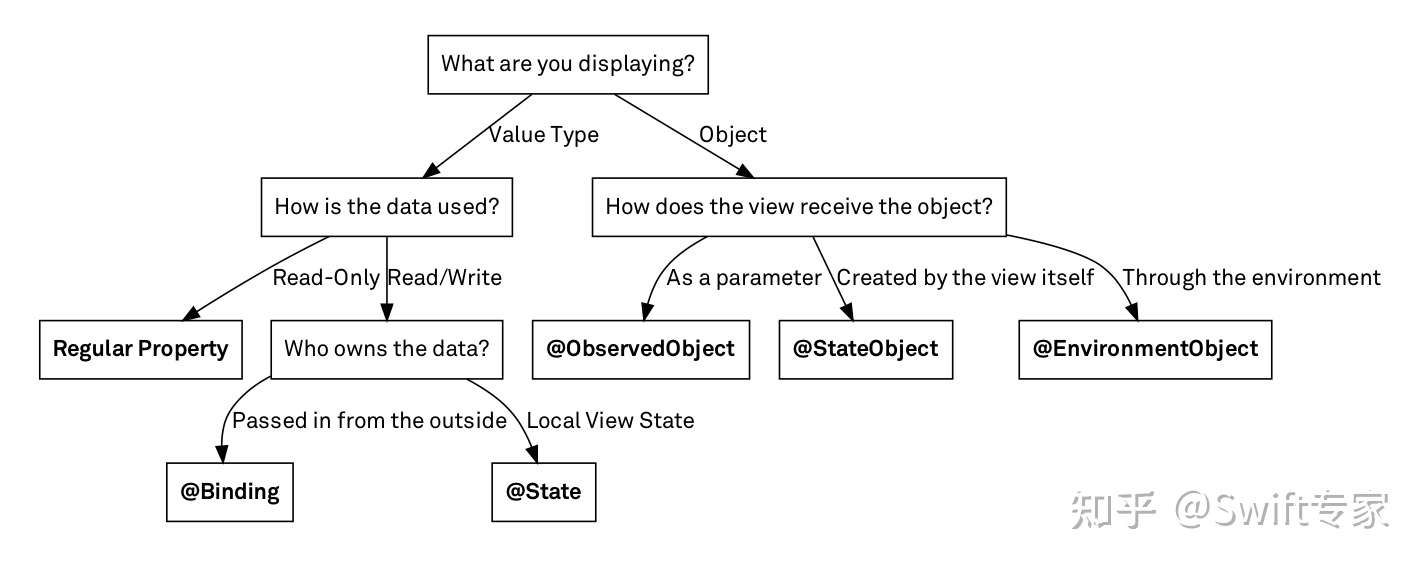
如果View依赖了这些数据,当数据改变的时候,View就会刷新。我们主要讲解ObservedObject和StateObject。
ObservedObject
class MyViewModel: ObservableObject {
@Published var name: String = "张三"
}
struct ContentView: View {
@ObservedObject var dataModel: MyViewModel
var body: some View {
Text(dataModel.name)
}
}
上边的代码是最常见的一种用法,dataModel为ContentView提供数据,那么@ObservedObject是怎么一回事呢?看它的定义:
@propertyWrapper @frozen public struct ObservedObject<ObjectType> : DynamicProperty where ObjectType : ObservableObject {
@dynamicMemberLookup @frozen public struct Wrapper {
public subscript<Subject>(dynamicMember keyPath: ReferenceWritableKeyPath<ObjectType, Subject>) -> Binding<Subject> { get }
}
public init(initialValue: ObjectType)
public init(wrappedValue: ObjectType)
public var wrappedValue: ObjectType
public var projectedValue: ObservedObject<ObjectType>.Wrapper { get }
}
通过分析上边的代码,我们发现下边几个重要信息:
ObjectType : ObservableObject表示它的类型必须实现ObservableObject协议,这个协议我们下边会讲到projectedValue: ObservedObject<ObjectType>.Wrapper,说明我们可以用$dataModel来访问这个projectedValue,它的返回值是Wrapper类型,再看上边struct Wrapper的定义,它是一个@dynamicMemberLookup,@dynamicMemberLookup的实现原理我们后续再详细讲解,大家只需要知道,当我们想要一个Bind类型的数据是,可以这样TextField("输入文字", text: $dataModel.name)
其中,上边的重点是ObservableObject协议,我们再看看它的定义:
public protocol ObservableObject : AnyObject {
/// The type of publisher that emits before the object has changed.
associatedtype ObjectWillChangePublisher : Publisher = ObservableObjectPublisher where Self.ObjectWillChangePublisher.Failure == Never
/// A publisher that emits before the object has changed.
var objectWillChange: Self.ObjectWillChangePublisher { get }
}
extension ObservableObject where Self.ObjectWillChangePublisher == ObservableObjectPublisher {
/// A publisher that emits before the object has changed.
public var objectWillChange: ObservableObjectPublisher { get }
}
ObservableObject继承自AnyObject,这说明了实现该协议必须是class类型,而不能是struct类型。
该协议要求返回一个objectWillChange属性,该属性必须实现Publisher协议,上边代码中的ObservableObject扩展已经实现了该协议,它返回的类型为ObservableObjectPublisher,我们再看看它的定义:
final public class ObservableObjectPublisher : Publisher {
/// The kind of values published by this publisher.
public typealias Output = Void
/// The kind of errors this publisher might publish.
///
/// Use `Never` if this `Publisher` does not publish errors.
public typealias Failure = Never
/// Creates an observable object publisher instance.
public init()
final public func receive<S>(subscriber: S) where S : Subscriber, S.Failure == ObservableObjectPublisher.Failure, S.Input == ObservableObjectPublisher.Output
final public func send()
}
可以看出ObservableObjectPublisher是一个很普通的Publisher,它是一个自定义的Publisher,对外只暴露了一个send方法,用于通知数据发生变更,这个Publisher并不会输出任何数据。
到目前为止,我们已经知道,只要实现了ObservableObject协议,就能获得一个objectWillChange,它是一个Publisher,只要调用objectWillChange.send()就可以触发View的刷新。
我们先实现这个协议,代码如下:
class MyViewModel: ObservableObject {
@Published var name: String = "张三"
var age: Int = 20
func click() {
age = 30
objectWillChange.send()
}
}
如果我们用@Published来包装某个属性,那么当属性的值变化时,就会自动调用objectWillChange.send(),否则我们需要手动调用。
我们再看一下@Published的定义:
@propertyWrapper public struct Published<Value> {
public init(wrappedValue: Value)
public init(initialValue: Value)
/// A publisher for properties marked with the `@Published` attribute.
public struct Publisher : Publisher {
/// The kind of values published by this publisher.
public typealias Output = Value
/// The kind of errors this publisher might publish.
///
/// Use `Never` if this `Publisher` does not publish errors.
public typealias Failure = Never
public func receive<S>(subscriber: S) where Value == S.Input, S : Subscriber, S.Failure == Published<Value>.Publisher.Failure
}
public var projectedValue: Published<Value>.Publisher { mutating get set }
}
大家只需要记住一点,它的projectedValue是一个Publisher,要想获取到这个projectedValue,使用$符号,因为它是一个Publisher,所有我们就可以随意使用Combine中的内容了:
$name
.map {
"姓名是: \($0)"
}
.sink(receiveValue: {
print($0)
})
StateObject
@StateObject和@ObservedObject都是用来包装实现了ObservableObject协议的属性,唯一的区别就是该属性的生命周期的管理问题。
@StateObject的生命周期由View管理,只初始化一次,View销毁它就销毁@ObservedObject的生命周期由我们手动管理,通常由父传给子
总结
本文并没有详细地讲解SwiftUI中的全部状态管理,只讲到了跟Combine有关系的状态,其中,最核心的是ObservableObject协议,在真实的开发中,它绝对是最常用的技术,我们自定义的View Model中,通过组合使用一系列的pipline来操作数据,当作为Source for Truth的数据变更后,View自动进行刷新。
Combine之实战(应用)
没有写过完整SwiftUI项目的同学,应该没怎么使用过Combine,可以这么说,**Combine就是专门用于处理数据的利器,**如果你学会了这些知识,那么你写SwiftUI程序的效率绝对会成倍的增加。
前边已经写了很多篇文章详细介绍了Combine中的Publisher,Operator,Subscriber,相信大家已经对Combine有了一个基本的了解,今天就带领大家一起研究一下Combine的实际应用。
大家可以在这里找到SwiiftUI和Combine的合集:FuckingSwiftUI
本文演示demo下载地址:CombineDemoTest
模拟网络搜索


上图演示了一个开发中最常见的场景,实时地根据用户的输入进行搜索,这样一个功能表面上看起来非常简单,其实内部逻辑细节很多:
- 需要为用户输入设置一个网络请求的间隔时间,比如当用户停止输入0.5秒后才发送请求,避免浪费不必要的网络资源
- 去重
- 显示loading状态
先看一下首页的代码:
struct ContentView: View {
@StateObject private var dataModel = MyViewModel()
@State private var showLogin = false;
var body: some View {
GeometryReader { geometry in
VStack(alignment: .leading, spacing: 0) {
ZStack {
HStack(spacing: 10) {
Group {
if dataModel.loading {
ActivityIndicator()
} else {
Image(systemName: "magnifyingglass")
}
}
.frame(width: 30, height: 30)
TextField("请输入要搜索的repository", text: $dataModel.inputText)
.textFieldStyle(RoundedBorderTextFieldStyle())
Button("登录") {
self.showLogin.toggle()
}
}
.padding(.vertical, 10)
.padding(.horizontal, 15)
}
.frame(width: geometry.size.width, height: 44)
.background(Color.orange)
List(dataModel.repositories) { res in
GithubListCell(repository: res)
}
}
}
.sheet(isPresented: $showLogin) {
LoginView()
}
}
}
上边代码非常简单,没有任何数据相关的处理逻辑,这些处理数据的逻辑全都在MyViewModel中进行,妙的地方在于,如果View中依赖了MyViewModel后,那么当MyViewModel数据改编后,View自动刷新。
- 我们使用
@StateObject初始化dataModel,让View管理其生命周期 - 使用
GeometryReader可以获取到父View的frame GithubListCell是每个仓库cell的封装,代码就不贴上来了,可以下载代码查看
重点来了,我们看看MyViewModel中的内容:
final class MyViewModel: ObservableObject {
@Published var inputText: String = ""
@Published var repositories = [GithubRepository]()
@Published var loading = false
var cancellable: AnyCancellable?
var cancellable1: AnyCancellable?
let myBackgroundQueue = DispatchQueue(label: "myBackgroundQueue")
init() {
cancellable = $inputText
// .debounce(for: 1.0, scheduler: myBackgroundQueue)
.throttle(for: 1.0, scheduler: myBackgroundQueue, latest: true)
.removeDuplicates()
.print("Github input")
.map { input -> AnyPublisher<[GithubRepository], Never> in
let originalString = "https://api.github.com/search/repositories?q=\(input)"
let escapedString = originalString.addingPercentEncoding(withAllowedCharacters: .urlQueryAllowed)!
let url = URL(string: escapedString)!
return GithubAPI.fetch(url: url)
.decode(type: GithubRepositoryResponse.self, decoder: JSONDecoder())
.map {
$0.items
}
.replaceError(with: [])
.eraseToAnyPublisher()
}
.switchToLatest()
.receive(on: RunLoop.main)
.assign(to: \.repositories, on: self)
cancellable1 = GithubAPI.networkActivityPublisher
.receive(on: RunLoop.main)
.assign(to: \.loading, on: self)
}
}
在这里,我会大概讲解主要代码的用途,不会太过详细,因为这些内容在之前的文章中已经详细讲过了。
$inputText:当我们在用@Published装饰过的属性前边加一个$符号后,就能获取一个Publisher.debounce(for: 1.0, scheduler: myBackgroundQueue): 当有输入时,debounce就会开启一个1秒的时间窗口,如果在1秒内收到了新的数据,则再开启一个新的1秒的时间窗口,之前的窗口作废,直到1秒内没有新的数据,然后发送最后收到的数据,它的核心思想是可以控制频繁的数据发送问题.throttle(for: 1.0, scheduler: myBackgroundQueue, latest: true): throttle会开启一系列连续的1秒的时间窗口,每次达到1秒的临界点就发送最近的一个数据,注意,当收到第一个数据时,会立刻发送。.removeDuplicates()可以去重,比如,当最近收到的两个数据都是swift时,第二个就会被忽略.print("Github input")可以打印pipline的过程,可以给输出信息加上前缀.map: 上边map的逻辑是把输入的字符串映射成一个新的Publisher,这个新的Publisher会请求网络,最终输出我们封装好的数据模型GithubRepositoryResponse.self.decode用于解析数据.replaceError(with: [])用于替换错误,如果网络请求出错,则发送一个空的数组.switchToLatest()用于输出Publisher的数据,如果map返回的是Publisher,就要使用switchToLatest切换输出.receive(on: RunLoop.main)用于切换线程.assign(to: \.repositories, on: self): assign可以直接使用KeyPath的形式为属性复制,它是一个Subscriber
大家看到了吗? 在一个完整的处理过程中,用到了很多Operators,通过组合使用这些Operator,几乎能实现任何需求。
我们再看看 GithubAPI的封装:
enum GithubAPIError: Error, LocalizedError {
case unknown
case apiError(reason: String)
case networkError(from: URLError)
var errorDescription: String? {
switch self {
case .unknown:
return "Unknown error"
case .apiError(let reason):
return reason
case .networkError(let from):
return from.localizedDescription
}
}
}
struct GithubAPI {
/// 加载
static let networkActivityPublisher = PassthroughSubject<Bool, Never>()
/// 请求数据
static func fetch(url: URL) -> AnyPublisher<Data, GithubAPIError> {
return URLSession.shared.dataTaskPublisher(for: url)
.handleEvents(receiveCompletion: { _ in
networkActivityPublisher.send(false)
}, receiveCancel: {
networkActivityPublisher.send(false)
}, receiveRequest: { _ in
networkActivityPublisher.send(true)
})
.tryMap { data, response in
guard let httpResponse = response as? HTTPURLResponse else {
throw GithubAPIError.unknown
}
switch httpResponse.statusCode {
case 401:
throw GithubAPIError.apiError(reason: "Unauthorized")
case 403:
throw GithubAPIError.apiError(reason: "Resource forbidden")
case 404:
throw GithubAPIError.apiError(reason: "Resource not found")
case 405..<500:
throw GithubAPIError.apiError(reason: "client error")
case 500..<600:
throw GithubAPIError.apiError(reason: "server error")
default: break
}
return data
}
.mapError { error in
if let err = error as? GithubAPIError {
return err
}
if let err = error as? URLError {
return GithubAPIError.networkError(from: err)
}
return GithubAPIError.unknown
}
.eraseToAnyPublisher()
}
}
GithubAPIError是对各种Error的一个封装,有兴趣可以看看Alamofirez中的AFErrornetworkActivityPublisher是一个Subject,本质上也是一个Publisher,用于发送网络加载的通知事件,大家可以看上边视频左上角的loading,就是用networkActivityPublisher实现的URLSession.shared.dataTaskPublisher(for: url)是最常见的网络请求Publisher.handleEvents可以监听pipline中的事件.tryMap是一种特殊的Operator,它主要用于数据映射,但允许throw异常.mapError用于处理错误信息,,在上边的代码中,我们做了错误映射的逻辑,错误映射的核心思想是把各种各样的错误映射成自定义的错误类型.eraseToAnyPublisher()用于磨平Publisher的类型,这个就不多做介绍了
总结一下,很多同学可能无法立刻体会到上边代码的精妙之处,响应式编程的妙处就在于我们提前铺设好数据管道,数据就会自动在管道中流动,实在是秒啊。
模拟登录
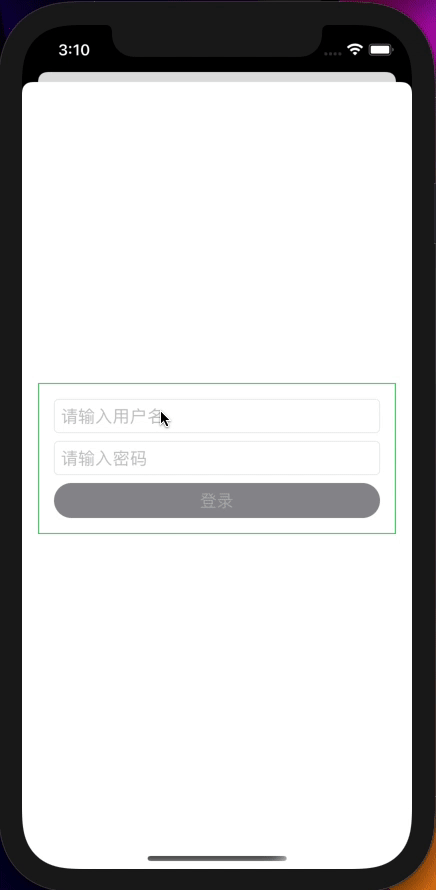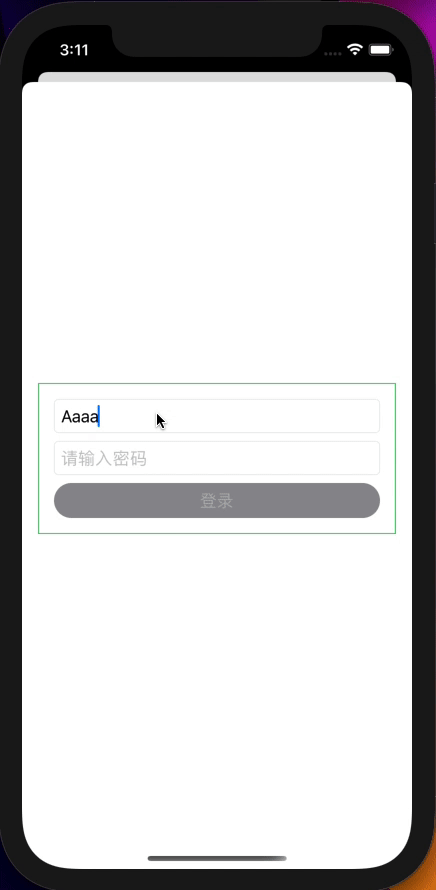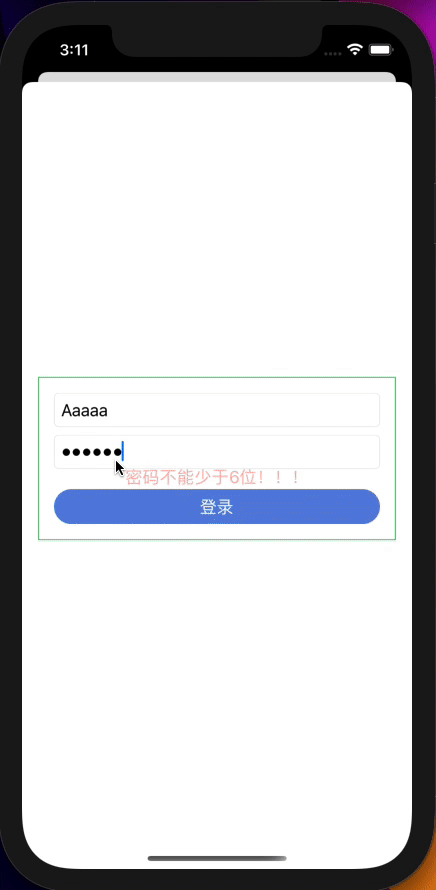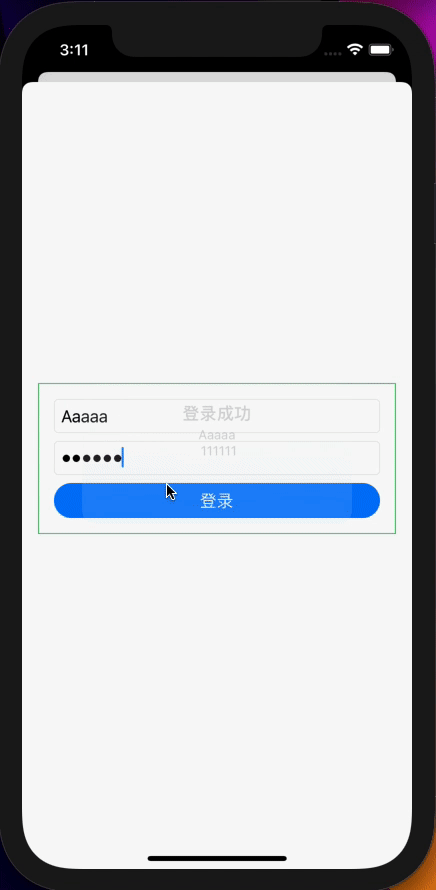
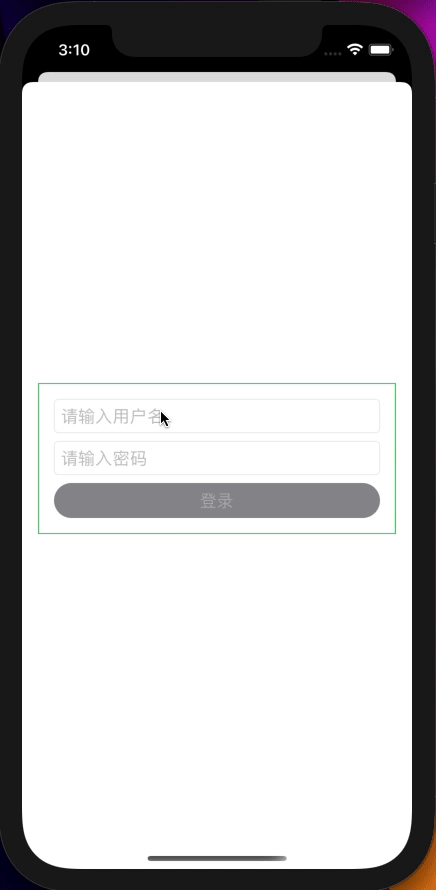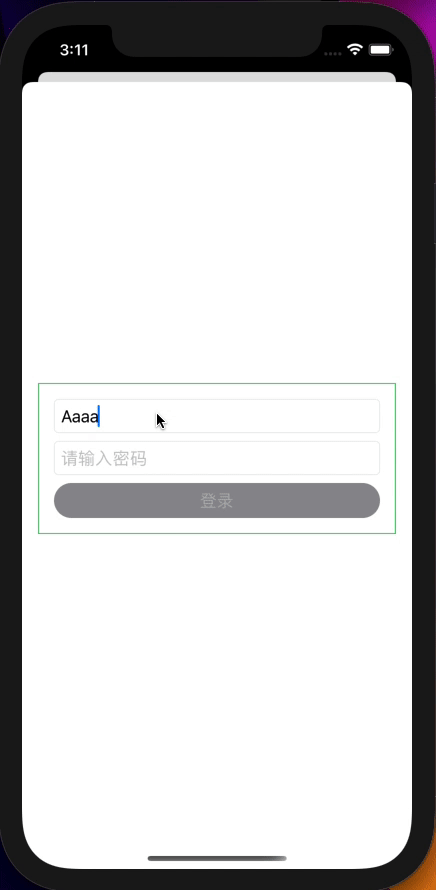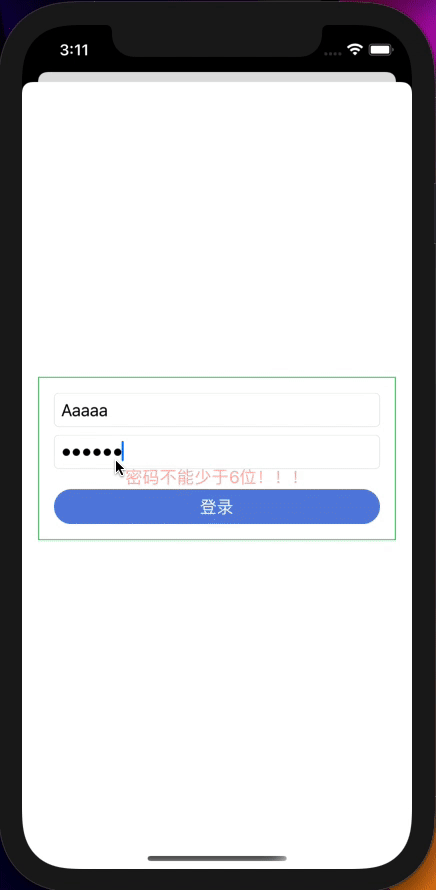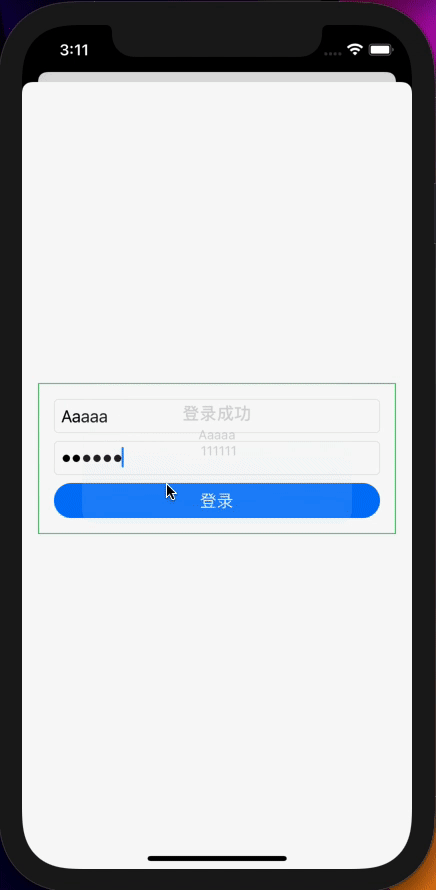
如果说网络请求是对异步数据的处理,那么模拟登录就是对多个数据流的处理,让我们先简单看一下UI代码:
struct LoginView: View {
@StateObject private var dataModel = LoginDataModel()
@State private var showAlert = false
var body: some View {
VStack {
TextField("请输入用户名", text: $dataModel.userName)
.textFieldStyle(RoundedBorderTextFieldStyle())
if dataModel.showUserNameError {
Text("用户名不能少于3位!!!")
.foregroundColor(Color.red)
}
SecureField("请输入密码", text: $dataModel.password)
.textFieldStyle(RoundedBorderTextFieldStyle())
if dataModel.showPasswordError {
Text("密码不能少于6位!!!")
.foregroundColor(Color.red)
}
GeometryReader { geometry in
Button(action: {
self.showAlert.toggle()
}) {
Text("登录")
.foregroundColor(dataModel.buttonEnable ? Color.white : Color.white.opacity(0.3))
.frame(width: geometry.size.width, height: 35)
.background(dataModel.buttonEnable ? Color.blue : Color.gray)
.clipShape(Capsule())
}
.disabled(!dataModel.buttonEnable)
}
.frame(height: 35)
}
.padding()
.border(Color.green)
.padding()
.animation(.easeInOut)
.alert(isPresented: $showAlert) {
Alert(title: Text("登录成功"),
message: Text("\(dataModel.userName) \n \(dataModel.password)"),
dismissButton: nil)
}
.onDisappear {
dataModel.clear()
}
}
}
具体涉及到SwiftUI的知识就不再复述了,套路都是相同的,在上边的UI代码中,我们直接拿LoginDataModel来使用,所有的业务逻辑都封装在LoginDataModel之中。
class LoginDataModel: ObservableObject {
@Published var userName: String = ""
@Published var password: String = ""
@Published var buttonEnable = false
@Published var showUserNameError = false
@Published var showPasswordError = false
var cancellables = Set<AnyCancellable>()
var userNamePublisher: AnyPublisher<String, Never> {
return $userName
.receive(on: RunLoop.main)
.map { value in
guard value.count > 2 else {
self.showUserNameError = value.count > 0
return ""
}
self.showUserNameError = false
return value
}
.eraseToAnyPublisher()
}
var passwordPublisher: AnyPublisher<String, Never> {
return $password
.receive(on: RunLoop.main)
.map { value in
guard value.count > 5 else {
self.showPasswordError = value.count > 0
return ""
}
self.showPasswordError = false
return value
}
.eraseToAnyPublisher()
}
init() {
Publishers
.CombineLatest(userNamePublisher, passwordPublisher)
.map { v1, v2 in
!v1.isEmpty && !v2.isEmpty
}
.receive(on: RunLoop.main)
.assign(to: \.buttonEnable, on: self)
.store(in: &cancellables)
}
func clear() {
cancellables.removeAll()
}
deinit {
}
}
仔细观察上边的代码,它是声明式的,对各个数据的处理是如此的清晰:
- 我们使用
userNamePublisher来处理用户名的逻辑 - 我们使用
passwordPublisher来处理密码的逻辑 - 我们使用
CombineLatest来合并用户名和密码的数据,用于控制登录按钮的状态
它确实是声明式的,如果从上往下看,它很像一份说明书,而不是一堆变量的计算。
在此,我也懒得写非Combine的对照代码了,大家可以仔细理解代码,细细品味其中韵味。
总结
本文写的不算复杂,也不算全面,并非一个完整的实战内容,只是让大家看一下Combine在真实开发场景的例子。本教程后续还有3篇文章,分别讲解如何自定义Publisher,Operator和Subscriber,算是进阶内容,大家拭目以待吧。
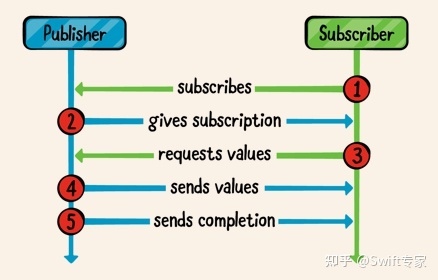
Combine之自定义Operator
自定义Operator是整个Combine教程中难度最高的内容,因为它连接了Publisher和Subscriber,起到了一个中间桥梁的作用。
那么难点在哪里呢?我希望读者朋友能够带着下边3个问题来仔细读这篇文章:
- 如何接收上游Publisher的数据?
- 下游可能是Operator,也可能是Subscriber,如何处理这种情况?
- 当下游是Subscriber时,如何接收其请求,并传播给上游?
上边3个问题就是本文的核心,下边的讲解的代码来自CombineExt
查看全部Combine教程,请访问:FuckingSwiftUI
最简单的自定义Operator
所谓的组合就是指使用已有的Publisher和Operator组合成具有新功能的Operator,举个例子:
public extension Publisher where Output: Collection {
func mapMany<Result>(_ transform: @escaping (Output.Element) -> Result) -> Publishers.Map<Self, [Result]> {
map { $0.map(transform) }
}
}
上边代码中的.mapMany()就是通过组合生成的一个新的Operator,它的用法如下:
let intArrayPublisher = PassthroughSubject<[Int], Never>()
intArrayPublisher
.mapMany(String.init)
.sink(receiveValue: { print($0) })
intArrayPublisher.send([10, 2, 2, 4, 3, 8])
// Output: ["10", "2", "2", "4", "3", "8"]
可以看出,.mapMany()的功能就是按照给出的规则映射Collection中的所有元素,上边的代码是非常简单的,我们可以模仿这种模式来组合生成任何其他的Operator。
有意思的一点是,.mapMany()输出类型通过代码public extension Publisher where Output: Collection约束成了Collection。也就是说该Operator的输入数据必须是Collection。
当然,大多数情况下没必要像上边这样写代码,这个看个人的喜好,上边的代码与下边的代码等价:
let intArrayPublisher = PassthroughSubject<[Int], Never>()
cancellable = intArrayPublisher
.map {
$0.map { String($0) }
}
.sink(receiveValue: { print($0) })
intArrayPublisher.send([10, 2, 2, 4, 3, 8])
完全自定义Operator
我们将会使用CombineExt中的amb来演示如何自定义Operator,要想弄明白本文的内容,前提条件是对Combine有一定的了解,对CombineExt有一定的研究,迫切想知道如何自定义Operator。再回到amb,它是一个非常有意思的Operator,我们先看看它的用法:
let subject1 = PassthroughSubject<Int, Never>()
let subject2 = PassthroughSubject<Int, Never>()
subject1
.amb(subject2)
.sink(receiveCompletion: { print("amb: completed with \($0)") },
receiveValue: { print("amb: \($0)") })
subject2.send(3) // Since this subject emit first, it becomes the active publisher
subject1.send(1)
subject2.send(6)
subject1.send(8)
subject1.send(7)
subject1.send(completion: .finished)
// Only when subject2 finishes, amb itself finishes as well, since it's the active publisher
subject2.send(completion: .finished)
打印结果:
amb: 3
amb: 6
amb: completed with .finished
从上边的代码可以看出,subject1和subject2谁先发送数据谁就会被激活,另一个则被忽略,这种行为很像是淘汰赛,只有第一名才会被保留。
这个Operator特别适合讲解如何自定义Operator,因为它的用法不算复杂,接下来我们就进入正题。
要想讲述清楚amb的创作过程,我们需要反向推演,我们先看看当我们调用了下边代码后,是怎样的一个过程:
subject1
.amb(subject2)
public extension Publisher {
func amb<Other: Publisher>(_ other: Other)
-> Publishers.Amb<Self, Other> where Other.Output == Output, Other.Failure == Failure {
Publishers.Amb(first: self, second: other)
}
}
从上边的代码中,我们可以分析出以下几点信息:
amb()函数的入参必须是一个Publisher,这算是一个约束条件amb()函数的返回值是Publishers.Amb,同样也是一个Publisher,后边给出的约束条件约束了这两个Publisher的输入和输出类型必须相同
从上边的代码可以看出,所谓的Operator就是Publisher协议的一个extension,因此我们能够获取到当前的Publisher,然后这个函数中需要返回一个Publisher,这样就实现了链式调用。
因此,现在的问题指向了Publishers.Amb,我们需要解决的问题是:如何处理上边提到的淘汰逻辑?如何响应Subscriber的订阅和请求?
我们看看Publishers.Amb的代码:
public extension Publishers {
struct Amb<First: Publisher, Second: Publisher>: Publisher where First.Output == Second.Output, First.Failure == Second.Failure {
public func receive<S: Subscriber>(subscriber: S) where Failure == S.Failure, Output == S.Input {
subscriber.receive(subscription: Subscription(first: first,
second: second,
downstream: subscriber))
}
public typealias Output = First.Output
public typealias Failure = First.Failure
private let first: First
private let second: Second
public init(first: First,
second: Second) {
self.first = first
self.second = second
}
}
}
代码看起来非常简单,只是持有了这2个Publisher,由于Amb实现了Publisher协议,那么重点就在于如何处理订阅的逻辑了:
Subscription(first: first,
second: second,
downstream: subscriber)
在以前的文章中,我们提到过,Subscription是沟通Publisher和Subscriber的一座桥梁,因此,这个Subscription里边的逻辑就显得非常重要。
我们看看它的代码:
private extension Publishers.Amb {
class Subscription<Downstream: Subscriber>: Combine.Subscription where Output == Downstream.Input, Failure == Downstream.Failure {
private var firstSink: Sink<First, Downstream>?
private var secondSink: Sink<Second, Downstream>?
private var preDecisionDemand = Subscribers.Demand.none
private var decision: Decision? {
didSet {
guard let decision = decision else { return }
switch decision {
case .first:
secondSink = nil
case .second:
firstSink = nil
}
request(preDecisionDemand)
preDecisionDemand = .none
}
}
init(first: First,
second: Second,
downstream: Downstream) {
self.firstSink = Sink(upstream: first,
downstream: downstream) { [weak self] in
guard let self = self,
self.decision == nil else { return }
self.decision = .first
}
self.secondSink = Sink(upstream: second,
downstream: downstream) { [weak self] in
guard let self = self,
self.decision == nil else { return }
self.decision = .second
}
}
func request(_ demand: Subscribers.Demand) {
guard decision != nil else {
preDecisionDemand += demand
return
}
firstSink?.demand(demand)
secondSink?.demand(demand)
}
func cancel() {
firstSink = nil
secondSink = nil
}
}
}
上边的代码比较长,我们拆分一下,我们先看初始化方法:
init(first: First,
second: Second,
downstream: Downstream) {
self.firstSink = Sink(upstream: first,
downstream: downstream) { [weak self] in
guard let self = self,
self.decision == nil else { return }
self.decision = .first
}
self.secondSink = Sink(upstream: second,
downstream: downstream) { [weak self] in
guard let self = self,
self.decision == nil else { return }
self.decision = .second
}
}
downstream在这里就是Subscriber,Sink我们先别管,下边会解释,现在只需要把它当作一个新的桥梁,它能够连接Publisher和Subscriber。
上边firstSink的Sink初始化函数中的闭包的调用时机是: 当第一次收到first这个Publisher的事件时调用,不管是收到数据还是收到完成事件,这个我们在后续讲解Sink的时候会讲解。
同理,secondSink跟firstSink差不多,在上边的初始化函数中,我们就找到了上边第一个问题的答案,当第一次收到first或second的事件后,就为decision赋值了,decision是一个enum,因此他是可以区分是first还是second。
private enum Decision {
case first
case second
}
到目前为止,大家应该仍然是糊涂的,因为大家对Sink还不是很了解, 我们必须先把这个Sink讲解了才能继续下去:
class Sink<Upstream: Publisher, Downstream: Subscriber>: Subscriber {
typealias TransformFailure = (Upstream.Failure) -> Downstream.Failure?
typealias TransformOutput = (Upstream.Output) -> Downstream.Input?
private(set) var buffer: DemandBuffer<Downstream>
private var upstreamSubscription: Subscription?
private let transformOutput: TransformOutput?
private let transformFailure: TransformFailure?
init(upstream: Upstream,
downstream: Downstream,
transformOutput: TransformOutput? = nil,
transformFailure: TransformFailure? = nil) {
self.buffer = DemandBuffer(subscriber: downstream)
self.transformOutput = transformOutput
self.transformFailure = transformFailure
upstream.subscribe(self)
}
func demand(_ demand: Subscribers.Demand) {
let newDemand = buffer.demand(demand)
upstreamSubscription?.requestIfNeeded(newDemand)
}
func receive(subscription: Subscription) {
upstreamSubscription = subscription
}
func receive(_ input: Upstream.Output) -> Subscribers.Demand {
...
}
func receive(completion: Subscribers.Completion<Upstream.Failure>) {
...
}
func cancelUpstream() {
upstreamSubscription.kill()
}
deinit { cancelUpstream() }
}
我省略了一些不重要的代码,我们仔细分析下上边的代码:
Sink实现了Subscriber协议,这说明了它本身就是一个订阅者,通常我们用它订阅upstream,这么做的目的是方便操作upstream输出的数据和request。DemandBuffer我们之前的文章已经讲过了,它做数据管理,只复杂把数据发送给downstreamtransformOutput和transformFailure数据转换函数,我们这里不讲了
Sink的核心思想就是通过亲自订阅上游的Publisher来接收数据和事件,通过DemandBuffer来管理这些数据和事件,当需要时,发送给下游的订阅者。
上边Sink的设计很重要,它是一个中间过程,本质上是因为它本身就是一个Subscriber订阅者,因此不仅能够获取到上游的数据,还剩自己控制发送rquest。
过程讲解
我们再重复一遍这个过程,先看下图:
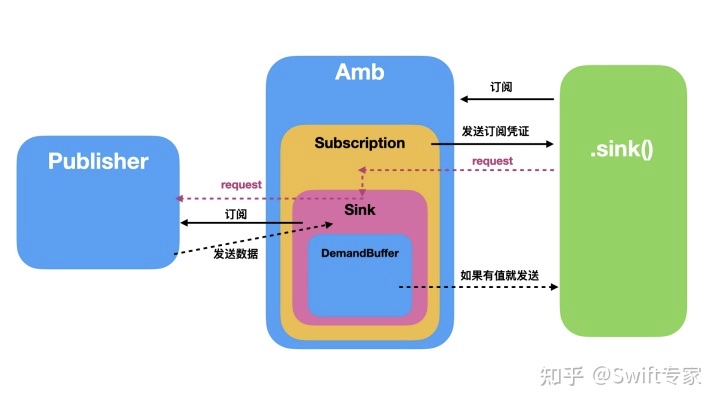
当执行下边代码时,究竟发生了什么?
subject1
.amb(subject2)
.sink(receiveCompletion: { print("amb: completed with \($0)") },
receiveValue: { print("amb: \($0)") })
subject1就是上图中的Publisher,.amb()返回了上图中的Amb, 当上边代码中调用了.sink()后,Amb就收到了订阅,会调用下边的代码:
public extension Publishers {
struct Amb<First: Publisher, Second: Publisher>: Publisher where First.Output == Second.Output, First.Failure == Second.Failure {
public func receive<S: Subscriber>(subscriber: S) where Failure == S.Failure, Output == S.Input {
subscriber.receive(subscription: Subscription(first: first,
second: second,
downstream: subscriber))
}
}
}
当收到订阅后,需要返回一个subscription,也就是订阅凭证,因为后边的Subscriber需要使用这个凭证来发送请求或者取消pipline。
由于上图中绿色的.sink()是系统方法,我们无法看到实现,但是,我们知道,当.sink()收到订阅凭证后就会发送request,也就是上图中的紫色虚线。
请注意,Amb里边的内容完全是我们自定义的,所以我们能够完全控制,当收到.sink()的request后,会调用Subscription下边的函数:
private extension Publishers.Amb {
class Subscription<Downstream: Subscriber>: Combine.Subscription where Output == Downstream.Input, Failure == Downstream.Failure {
...
func request(_ demand: Subscribers.Demand) {
guard decision != nil else {
preDecisionDemand += demand
return
}
firstSink?.demand(demand)
secondSink?.demand(demand)
}
...
}
}
.sink()传过来的demand的值是.unlimited,表示不限制数据的接收个数,观察上边的代码,decision表示当前使用的Publisher是哪个,subject1或者subject2谁第一个发送数据,decision就指向谁。
由于这个request是收到订阅凭证后立刻发出的,这时候subject1和subject2都没有发送数据,因此decision为nil,上边的代码就把.sink()传过来的demand保存在preDecisionDemand属性中了,后边会把这个demand透传给胜出的Publisher(subject1或subject2)。
那么重点来了,subject1,subject2竞争的代码在什么地方呢?答案是放在了上边Subscription初始化方法中了:
private extension Publishers.Amb {
class Subscription<Downstream: Subscriber>: Combine.Subscription where Output == Downstream.Input, Failure == Downstream.Failure {
private var firstSink: Sink<First, Downstream>?
private var secondSink: Sink<Second, Downstream>?
private var preDecisionDemand = Subscribers.Demand.none
private var decision: Decision? {
didSet {
guard let decision = decision else { return }
switch decision {
case .first:
secondSink = nil
case .second:
firstSink = nil
}
request(preDecisionDemand)
preDecisionDemand = .none
}
}
init(first: First,
second: Second,
downstream: Downstream) {
self.firstSink = Sink(upstream: first,
downstream: downstream) { [weak self] in
guard let self = self,
self.decision == nil else { return }
self.decision = .first
}
self.secondSink = Sink(upstream: second,
downstream: downstream) { [weak self] in
guard let self = self,
self.decision == nil else { return }
self.decision = .second
}
}
...
}
}
还记得Subscription什么时候初始化吗?就是当收到.sink()的订阅后创建的。上边的init()很简单,分别创建了两个Sink,firstSink代表subject1,secondSink代表subject2。
在上边的小节中,我们已经知道,Sink的闭包参数的调用时机是当收到第一个参数时调用,再结合上边的代码,我们就可以看出,当firstSink或者secondSink其中一个第一次收到数据后,就决定了decision的值,并且在decision的didSet中,这时候就选中了哪个Publisher作为发送数据的Publisher,另一个则赋值为nil,之后我们重新调用了request(preDecisionDemand),把之前保存的demand透传给胜出的Publisher。
此时此刻,我们的头脑中应该有两个疑问:
- 假设firstSink胜出了,那么调用
firstSink?.demand(demand)是如何实现把demand透传subject1的? - Sink是如何接收subject1或者subject2的数据的?
这两个问题的核心都指向了Sink,注意,这个Sink很有意思,本文的最上边也讲到了,它实现了Subscriber协议,这一点很重要,我们看看它的初始化方法中干了啥?
init(upstream: Upstream,
downstream: Downstream,
transformOutput: TransformOutput? = nil,
transformFailure: TransformFailure? = nil) {
self.buffer = DemandBuffer(subscriber: downstream)
self.transformOutput = transformOutput
self.transformFailure = transformFailure
upstream.subscribe(self)
}
看明白了吗?由于Sink本身就是一个Subscriber,因此,它订阅了传进来的上游Publisher。
func receive(subscription: Subscription) {
upstreamSubscription = subscription
}
并且能够拿到上游Publisher传过来的subscription,因此可以使用这个subscription发送request。
到此为止,上边的两个问题的答案已经呼之欲出了。
总结一下,Amb中自定义的Subscription作为沟通下游.sink()的桥梁接收request,Subscription中持有的Sink订阅了上游的Publisher,它作为Publisher和.sink()的中间桥梁,透传demand和数据。
那么回到开头的3个问题,你有答案了吗?
- 如何接收上游PubLisher的数据?
- 下游可能是Publisher或者其他Operator,也可能是Subscriber,如何处理这种情况?
- 当下游是Subscriber时,如何接收其请求,并传播给上游?
总结
当初特别好奇,Combine中的Operator是如何实现的?因为它确实比较特殊,它的上游是Publisher或者Operator,下游是Operator或Subscriber。本文讲解的内容可以作为一个套路来学习,如果需要自定义Operator,可以参考这篇文章。
Combine之自定义Publisher
在真实的开发中,我们几乎不会去自定义Publisher,但学习本文的知识还是很有必要的,接下来的3篇文章,我会讲解如何自定义Publisher,Operator和Subscriber,我尽量把这些内容讲清楚,通过这3篇文章的学习,能够让大家对Combine的实现原理有一个清晰的认识。
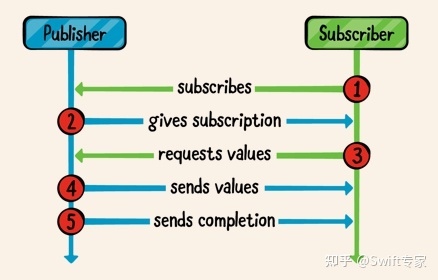
这篇文章的主要代码来源于CombineExt
组合
/// 请求数据
static func fetch(url: URL) -> AnyPublisher<Data, GithubAPIError> {
return URLSession.shared.dataTaskPublisher(for: url)
.handleEvents(receiveCompletion: { _ in
networkActivityPublisher.send(false)
}, receiveCancel: {
networkActivityPublisher.send(false)
}, receiveRequest: { _ in
networkActivityPublisher.send(true)
})
.tryMap { data, response in
guard let httpResponse = response as? HTTPURLResponse else {
throw GithubAPIError.unknown
}
switch httpResponse.statusCode {
case 401:
throw GithubAPIError.apiError(reason: "Unauthorized")
case 403:
throw GithubAPIError.apiError(reason: "Resource forbidden")
case 404:
throw GithubAPIError.apiError(reason: "Resource not found")
case 405..<500:
throw GithubAPIError.apiError(reason: "client error")
case 500..<600:
throw GithubAPIError.apiError(reason: "server error")
default: break
}
return data
}
.mapError { error in
if let err = error as? GithubAPIError {
return err
}
if let err = error as? URLError {
return GithubAPIError.networkError(from: err)
}
return GithubAPIError.unknown
}
.eraseToAnyPublisher()
}
上边的代码就是一个使用Operator组合的例子,我们并没有自定义任何Publisher,但最后我们生成了一个AnyPublisher<Data, GithubAPIError>类型的Publisher。
大家仔细想想,这种通过组合来实现某种功能的方式和自定义Publisher是不是没啥区别?也就是说,在开发中,尽可能的使用这种组合的方式解决问题。
自定义Create(一个新的Publisher)
我们这一小节将会演示一个完整的自定义Publisher的例子,Create这个Publisher的使用方法跟Combine中的Record很像,这是一个非常完美的示例,功能相同确能看到实现代码。Record的用法如下:
let recordPublisher = Record<String, MyCustomError> { recording in
recording.receive("你")
recording.receive("好")
recording.receive("吗")
recording.receive(completion: Subscribers.Completion.finished)
}
而Create的用法如下:
AnyPublisher<String, MyError>.create { subscriber in
// Values
subscriber.send("Hello")
subscriber.send("World!")
// Complete with error
subscriber.send(completion: .failure(MyError.someError))
// Or, complete successfully
subscriber.send(completion: .finished)
return AnyCancellable {
// Perform cleanup
}
}
在学习新技术的时候,我们要慢慢学会通过观察代码的使用方法,来尝试推断代码的设计思想。 我们尝试分析一下上边代码的思想:
AnyPublisher<String, MyError>.create表明create是AnyPublisher的一个静态函数,该函数接收一个闭包作为参数- 闭包的参数
subscriber至少有两个方法:send()和send(completion:),一个用于发送数据。一个用于发送完成事件 - 闭包返回
AnyCancellable - 重要的设计思想:使用闭包把数据的发送过程封装起来,当接收到订阅后,调用闭包,触发该过程
接下来,我们从代码层次来进一步分析上边代码的具体实现过程。
// MARK: - Publisher
@available(OSX 10.15, iOS 13.0, tvOS 13.0, watchOS 6.0, *)
public extension Publishers {
/// A publisher which accepts a closure with a subscriber argument,
/// to which you can dynamically send value or completion events.
///
/// You should return a `Cancelable`-conforming object from the closure in
/// which you can define any cleanup actions to execute when the pubilsher
/// completes or the subscription to the publisher is canceled.
struct Create<Output, Failure: Swift.Error>: Publisher {
public typealias SubscriberHandler = (Subscriber) -> Cancellable
private let factory: SubscriberHandler
/// Initialize the publisher with a provided factory
///
/// - parameter factory: A factory with a closure to which you can
/// dynamically push value or completion events
public init(factory: @escaping SubscriberHandler) {
self.factory = factory
}
public func receive<S: Combine.Subscriber>(subscriber: S) where Failure == S.Failure, Output == S.Input {
subscriber.receive(subscription: Subscription(factory: factory, downstream: subscriber))
}
}
}
当我们要自定义Publisher时,从宏观应该考虑以下2点:
- 写一个
Publishers的extension,方便导出类型,比如上边代码中,导出的类型就是Publishers.Create - 实现
Publisher协议,其中最核心的是要给subscriber发送一个Subscription,这个Subscription是最核心的内容,我们下边详细讲解
在上边的代码中,Create通过一个闭包(SubscriberHandler = (Subscriber) -> Cancellable)来进行初始化,我们先研究一下这个闭包,不难看出,闭包的参数是个Subscriber类型,我们看看它的代码:
public extension Publishers.Create {
struct Subscriber {
private let onValue: (Output) -> Void
private let onCompletion: (Subscribers.Completion<Failure>) -> Void
fileprivate init(onValue: @escaping (Output) -> Void,
onCompletion: @escaping (Subscribers.Completion<Failure>) -> Void) {
self.onValue = onValue
self.onCompletion = onCompletion
}
/// Sends a value to the subscriber.
///
/// - Parameter value: The value to send.
public func send(_ input: Output) {
onValue(input)
}
/// Sends a completion event to the subscriber.
///
/// - Parameter completion: A `Completion` instance which indicates whether publishing has finished normally or failed with an error.
public func send(completion: Subscribers.Completion<Failure>) {
onCompletion(completion)
}
}
}
上边的代码,包含了以下几条信息:
- Subscriber本身是一个struct
- 初始化方法需要传入两个private闭包:
onValue和onCompletion,不能在外部调用 - 当调用
subscriber.send("Hello")时,本质上是调用了onValue - 当调用
subscriber.send(completion: .finished)时,本质上是调用了onCompletion
总结一下:Subscriber对外暴露了两个函数接口,调用后,会触发闭包,至于闭包中的操作,我们在下文中会讲到。
接来下就是重点了,我们需要自定义Subscription,数据的处理逻辑都在它里边,它起到了一个承上启下的核心功能。
private extension Publishers.Create {
class Subscription<Downstream: Combine.Subscriber>: Combine.Subscription where Output == Downstream.Input, Failure == Downstream.Failure {
private let buffer: DemandBuffer<Downstream>
private var cancelable: Cancellable?
init(factory: @escaping SubscriberHandler,
downstream: Downstream) {
self.buffer = DemandBuffer(subscriber: downstream)
let subscriber = Subscriber(onValue: { [weak self] in _ = self?.buffer.buffer(value: $0) },
onCompletion: { [weak self] in self?.buffer.complete(completion: $0) })
self.cancelable = factory(subscriber)
}
func request(_ demand: Subscribers.Demand) {
_ = self.buffer.demand(demand)
}
func cancel() {
self.cancelable?.cancel()
}
}
}
所谓的自定义Subscription,就是实现Combine.Subscription协议,它有2个目的:
- 通过
func request(_ demand: Subscribers.Demand)接收订阅者的数据请求 - 通过
func cancel()接收订阅者的取消请求
仔细观察上边的代码就能够发现,Subscription的Output和Failure类型必须和下游的订阅者匹配上才行,并且引入了一个private let buffer: DemandBuffer<Downstream>属性作为数据的缓存单元。
self.buffer = DemandBuffer(subscriber: downstream)
上边这行代码显示,DemandBuffer使用downstream进行初始化,别忘了downstream是一个订阅者,也就是subscriber,在这里,大家只需要理解,DemandBuffer持有了subscriber就可以了。
let subscriber = Subscriber(onValue: { [weak self] in _ = self?.buffer.buffer(value: $0) },
onCompletion: { [weak self] in self?.buffer.complete(completion: $0) })
这行代码就和前边讲过的Subscriber联系上了,它的onValue闭包绑定了self?.buffer.buffer(value: $0),也就是当调用subscriber.send("Hello")后,实际上的操作是self?.buffer.buffer(value: "Hello"),同样的道理,它的onCompletion闭包绑定了self?.buffer.complete(completion: $0),也就是当调用subscriber.send(completion: .finished)后,实际上的操作是self?.buffer.complete(completion: .finished)。
self.cancelable = factory(subscriber)
这行代码才是Create初始化参数闭包的真正调用的地方。
大家应该已经发现了吧?自定义Subscription的核心在于如何做好数据管理,我们还需要搞明白DemandBuffer这个东西的实现原理,它在后边两篇文章中,也起到了核心作用。
最后,我们分析一波DemandBuffer的源码:
class DemandBuffer<S: Subscriber> {
private let lock = NSRecursiveLock()
private var buffer = [S.Input]()
private let subscriber: S
private var completion: Subscribers.Completion<S.Failure>?
private var demandState = Demand()
init(subscriber: S) {
self.subscriber = subscriber
}
func buffer(value: S.Input) -> Subscribers.Demand {
precondition(self.completion == nil,
"How could a completed publisher sent values?! Beats me ♂️")
switch demandState.requested {
case .unlimited:
return subscriber.receive(value)
default:
buffer.append(value)
return flush()
}
}
func complete(completion: Subscribers.Completion<S.Failure>) {
precondition(self.completion == nil,
"Completion have already occured, which is quite awkward ")
self.completion = completion
_ = flush()
}
func demand(_ demand: Subscribers.Demand) -> Subscribers.Demand {
flush(adding: demand)
}
private func flush(adding newDemand: Subscribers.Demand? = nil) -> Subscribers.Demand {
lock.lock()
defer { lock.unlock() }
if let newDemand = newDemand {
demandState.requested += newDemand
}
// If buffer isn't ready for flushing, return immediately
guard demandState.requested > 0 || newDemand == Subscribers.Demand.none else { return .none }
while !buffer.isEmpty && demandState.processed < demandState.requested {
demandState.requested += subscriber.receive(buffer.remove(at: 0))
demandState.processed += 1
}
if let completion = completion {
// Completion event was already sent
buffer = []
demandState = .init()
self.completion = nil
subscriber.receive(completion: completion)
return .none
}
let sentDemand = demandState.requested - demandState.sent
demandState.sent += sentDemand
return sentDemand
}
}
上边的代码虽然看上去很长,但内容并不多,我们可以把它分为3个部分:
- 初始化
- 对外接口
- 内部核心逻辑
我们先看看初始化的代码:
private let lock = NSRecursiveLock()
private var buffer = [S.Input]()
private let subscriber: S
private var completion: Subscribers.Completion<S.Failure>?
private var demandState = Demand()
init(subscriber: S) {
self.subscriber = subscriber
}
从属性let lock = NSRecursiveLock()不难看出,它为数据的操作增加了安全性,这是非常有必要的,因为pipline专门处理异步数据流。在平时的开发中,我们也可以使用这个锁来保证安全地操作数据,用法如下:
lock.lock()
defer { lock.unlock() }
从属性var buffer = [S.Input]()可以看出,它内部把数据保存在一个数据之中,数据的类型是Subscriber的输入类型。
从属性let subscriber: S可以看出,它持有了Subscriber,这个在后边的代码中会用到。
之所以把var completion: Subscribers.Completion<S.Failure>?这个属性保存起来,主要目的是数组buffer中不能存放该类型的数据,因此需要额外保存。
var demandState = Demand()表示当前的请求状态,它是一个独立的struct,源码如下:
private extension DemandBuffer {
/// A model that tracks the downstream's
/// accumulated demand state
struct Demand {
var processed: Subscribers.Demand = .none
var requested: Subscribers.Demand = .none
var sent: Subscribers.Demand = .none
}
}
这里的代码可能会让人疑惑,看一下Subscribers.Demand的定义:
/// A requested number of items, sent to a publisher from a subscriber through the subscription.
@frozen public struct Demand : Equatable, Comparable, Hashable, Codable, CustomStringConvertible {
/// A request for as many values as the publisher can produce.
public static let unlimited: Subscribers.Demand
/// A request for no elements from the publisher.
///
/// This is equivalent to `Demand.max(0)`.
public static let none: Subscribers.Demand
/// Creates a demand for the given maximum number of elements.
///
/// The publisher is free to send fewer than the requested maximum number of elements.
///
/// - Parameter value: The maximum number of elements. Providing a negative value for this parameter results in a fatal error.
@inlinable public static func max(_ value: Int) -> Subscribers.Demand
}
由于它实现了Equatable,Comparable和Hashable这3个协议,所有完全可以把它看作是一个数字,可以进行运算,也可以进行比较,.none可以看成0,.unlimited可以看成最大值,也可以用.max指定一个值。
那么这个值的作用是什么呢?很简单,它表示Subscriber(订阅者)能接受数据的最大个数。 我们看到下边这样的打印结果:
receive subscription: (PassthroughSubject)
request unlimited
就说明Subscriber(订阅者)可以接收任何数量的数据,没有限制。我们再回到前边的代码,var demandState = Demand()的初始状态都是.none。
接下来,我们看看第2部分的代码,主要是暴露出的接口,用于给外部调用:
func buffer(value: S.Input) -> Subscribers.Demand {
precondition(self.completion == nil,
"How could a completed publisher sent values?! Beats me ♂️")
switch demandState.requested {
case .unlimited:
return subscriber.receive(value)
default:
buffer.append(value)
return flush()
}
}
func complete(completion: Subscribers.Completion<S.Failure>) {
precondition(self.completion == nil,
"Completion have already occured, which is quite awkward ")
self.completion = completion
_ = flush()
}
func demand(_ demand: Subscribers.Demand) -> Subscribers.Demand {
flush(adding: demand)
}
buffer()用于处理缓存数据的部分逻辑,当收到外部的调用后,如果请求是不受限的,就直接发送数据给Subscriber,否则,把数据拼接到数组中,然后调用flush()complete()用于接收外部的完成事件,保存后调用flush()demand()是一个非常奇妙且重要的方法,它的目的是响应一个Demand请求,然后调用flush()处理这个响应,本质上这个函数中的参数的Demand请求就是Subscriber(订阅者)的请求。
我发现用文字讲知识确实比较费劲,没有视频好,大家再看看上边的自定义Subscription的代码:
func request(_ demand: Subscribers.Demand) {
_ = self.buffer.demand(demand)
}
Subscription实现了Combine.Subscription协议,func request(_ demand: Subscribers.Demand)正是协议中的方法,该方法会被Subscriber(订阅者)调用。
大家如果有任何疑问,可以留言。我们再看看第3部分的内容:
private func flush(adding newDemand: Subscribers.Demand? = nil) -> Subscribers.Demand {
lock.lock()
defer { lock.unlock() }
if let newDemand = newDemand {
demandState.requested += newDemand
}
// If buffer isn't ready for flushing, return immediately
guard demandState.requested > 0 || newDemand == Subscribers.Demand.none else { return .none }
while !buffer.isEmpty && demandState.processed < demandState.requested {
demandState.requested += subscriber.receive(buffer.remove(at: 0))
demandState.processed += 1
}
if let completion = completion {
// Completion event was already sent
buffer = []
demandState = .init()
self.completion = nil
subscriber.receive(completion: completion)
return .none
}
let sentDemand = demandState.requested - demandState.sent
demandState.sent += sentDemand
return sentDemand
}
上边代码很简单,就是当requested > 0的时候,把数据发送给Subscriber,DemandBuffer持有Subscriber的目的就是为了后边调用subscriber.receive(buffer.remove(at: 0))。我们再重新分析一下Subscription的过程:
首先,我们初始化:
init(factory: @escaping SubscriberHandler,
downstream: Downstream) {
self.buffer = DemandBuffer(subscriber: downstream)
let subscriber = Subscriber(onValue: { [weak self] in _ = self?.buffer.buffer(value: $0) },
onCompletion: { [weak self] in self?.buffer.complete(completion: $0) })
self.cancelable = factory(subscriber)
}
初始化成功后,buffer中的.flush()函数并不会把数据透传给Subscriber,当收到订阅接收到订阅者的request后调用下边的代码:
func request(_ demand: Subscribers.Demand) {
_ = self.buffer.demand(demand)
}
然后调用buffer中的.demand()函数,.demand()函数又调用.flush(),最终遍历数组,把数据全部透传给Subscriber。
如果大家有点蒙,只能多看代码和上边的解释,再细细品一下。
最后,我们回到起始的地方,再回过头来看下边的代码:
public extension AnyPublisher {
init(_ factory: @escaping Publishers.Create<Output, Failure>.SubscriberHandler) {
self = Publishers.Create(factory: factory).eraseToAnyPublisher()
}
static func create(_ factory: @escaping Publishers.Create<Output, Failure>.SubscriberHandler)
-> AnyPublisher<Output, Failure> {
AnyPublisher(factory)
}
}
总结
自定义Publisher的关键是自定义Subscription,Subscription又通过DemandBuffer管理数据,DemandBuffer的核心思想是把数据放入到数组中,然后通过func demand(_ demand: Subscribers.Demand) -> Subscribers.Demand释放数据。
Copyright © 2015 Powered by MWeb, 豫ICP备09002885号-5