iOS 中的 Promise 设计模式
做iOS开发的同学都非常熟悉代理模式,为避免代码耦合,代理模式的委托者任务交给代理执行,代理执行完毕之后再把回调告诉委托者。委托者不关心代理是怎么执行任务的,只关心结果是成功还是失败。代理模式就像是杀手与雇主的关系一样。
但是代理模式也不完美,代理多了,雇主也管不过来了,委托在A处,收结果却要在B处。有的时候,雇主也希望能在同一个地方既可以发配任务,也可以接收结果。闭包Block就能帮雇主解决这个问题了。无论是系统的GCD,还是平时随手封装一个 UIAlertView 的block实现,都让代码的可读性有了一定的提升。
无论是代理模式,还是闭包,在处理单一任务的时候,都出色的完成了任务。可是当两种模式要相互配合,一起完成一系列任务,并且每个任务之间还要共享信息,相互衔接,雇主就要头疼了。当然可以只用一种模式来实现,代理模式就不说了,过于分散,不善于处理这种流程性的事务。那我用闭包来举一个例子:我们需要顺序执行Task A、B、C 三个任务,A、B、C依次执行,任务完成之后都使用闭包来回调并开始下一个任务。代码如下:
- (void)callbackHell
{
dispatch_async(dispatch_get_global_queue(0, 0), ^{
[self doTaskA:^{
[self doTaskB:^{
[self doTaskC:^{
// all task done
}];
}];
}];
});
}
上面的代码看起来挺清晰,可读性也还可。如果加上一些 ifelse 的分支判断,再加上一些参数的传递,代码不知不觉的向右延伸,最终超出了屏幕的宽度,形成一个倒金字塔的形状。写 JavaScript 的同学会说:你已经掉进了回调陷阱(CallbackHell),赶紧用Promise设计模式来跳坑吧。
##Promise 设计模式的原理
Promise设计模式把每一个异步操作都封装成一个Promise对象,这个Promise对象就是这个异步操作执行完毕的结果,但是这个结果是可变的,就像薛定谔的猫,只有执行了才知道。通过这种方式,就能提前获取到结果,并处理下一步骤。
Promise 使用 then 作为关键字,回调最终结果。 then 是整个Promise设计模式的核心,必须要被实现。另外还有其它几个关键字用来表示一个Promise对象的状态:
-
pending: 任务执行中,状态可能会进入下面的fullfill或者reject二者之一
-
fufill/resolved: 任务完成了,返回结果
-
reject: 任务失败,并返回错误更多可以参考 官方规范。
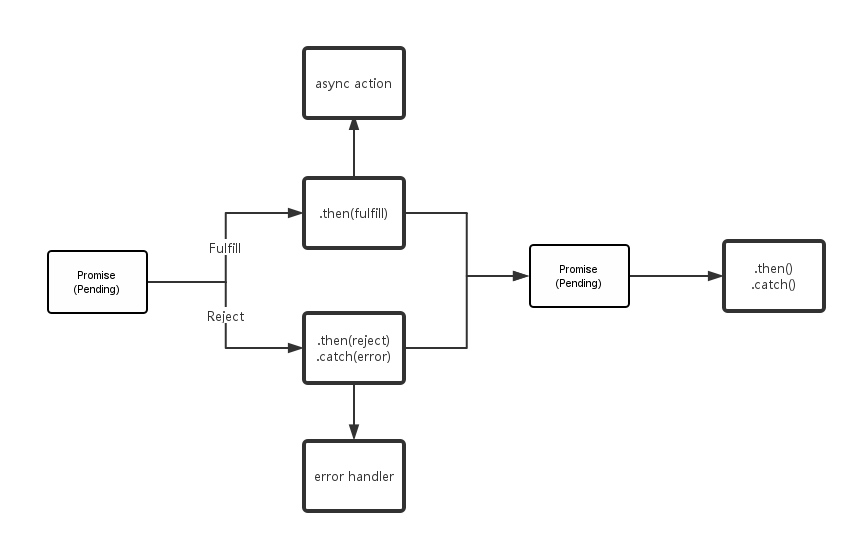
如上图所示,fullfill与reject的状态都是不可逆转的,保证了结果的唯一性。除了 then ,一些对 Promise 的实现还有几个关键字用来扩展,让代码可读性更强:
-
catch: 任务失败,处理error
-
finally: 无论是遇到 then 还是 catch 分支,最终都会执行的回调
-
when: 多个异步任务执行完毕之后才会回调
##Promise模式的实现
Promise设计模式在 iOS/MacOS 平台的最佳实践是由大名鼎鼎的homebrew的作者 Max Howell 写的一个支持iOS/MacOS 的异步编程框架 – PromiseKit , 作者的另一个广为人知的趣事是因为没有写出反转二叉树而没有拿到Google的offer。
我们先抛出对上面改良函数使用PromiseKit的实现,再看原理:
- (void)jumpOutCallbackHell
{
[self promiseTaskA].then(^{
return [self promiseTaskB];
}).then(^{
return [self promiseTaskC];
}).then(^{
NSLog(@"all task done");
});
}
调试后,发现执行的结果与我们期待的一致,但是上面的代码对我来说有几个疑惑点:
then 是怎么串起来的;
怎么实现的顺序调用;
如果传递参数,参数是怎么传递的。
带着问题,来看Promise的源码:
- (PMKPromise *(^)(id))then {
return ^(id block){
return self.thenOn(dispatch_get_main_queue(), block);
};
}
如果对block不是很熟悉,可能不太理解这段代码,实际上,PromiseKit灵活的使用了block作为函数的返回值来实现链式调用。相比原来的block嵌套模式,PromiseKit使用block将多个 then 串联起来,解决了callback hell。
接着来继续看下一个问题。
- (id)resolved:(PMKResolveOnQueueBlock(^)(id result))mkresolvedCallback
pending:(void(^)(id result, PMKPromise *next, dispatch_queue_t q, id block, void (^resolver)(id)))mkpendingCallback
{
__block PMKResolveOnQueueBlock callBlock;
__block id result;
dispatch_sync(_promiseQueue, ^{
if ((result = _result))
return;
callBlock = ^(dispatch_queue_t q, id block) {
block = [block copy];
__block PMKPromise *next = nil;
dispatch_barrier_sync(_promiseQueue, ^{
if ((result = _result))
return;
__block PMKPromiseFulfiller resolver;
next = [PMKPromise new:^(PMKPromiseFulfiller fulfill, PMKPromiseRejecter reject) {
resolver = ^(id o){
if (IsError(o)) reject(o); else fulfill(o);
};
}];
[_handlers addObject:^(id value){
mkpendingCallback(value, next, q, block, resolver);
}];
});
return next ?: mkresolvedCallback(result)(q, block);
};
});
return callBlock ?: mkresolvedCallback(result);
}
代码有点长,不过也可以理解。这个方法是上面的thenon调用的,接受两个参数,第一个参数是一个resolve的block,第二个参数是一个pending的block。一个Promise在执行完毕之后,无论状态是变成resolve还是pending,都通过这个方法,执行对应的 then,并返回一个Promise对象。上面的函数中,有一个dispatch_barrier_sync ,barrier是栅栏的意思,一般来说如果我们有多个异步任务,但是希望他们按照一定的顺序执行,就可以使用这个方法。在这里PromiseKit通过barrier实现了then的依次调用。在这个barrier方法内部,一个是会去看当前是否已经有下一个要执行的Promise,如果没有就生成一个新的,另一个把对应的pending 放到handler队列,依次执行。
##参数传递
这里需要思考的另外一个问题是,既然多个任务之间有依次调用的关系,那么这样的一种任务流之间如何互相通信呢?PromiseKit用了一个比较有趣的办法来实现相邻Promise对象的参数传递。
在万物皆消息的OC语言内部,每一个方法,包括Block在内都是有类型签名的。这个类型签名对象就是 NSMethodSignature
@interface NSMethodSignature : NSObject {
...
@property (readonly) NSUInteger numberOfArguments;
...
@property (readonly) const char *methodReturnType NS_RETURNS_INNER_POINTER;
...
@end
那么对于block,怎么获取类型签名呢?PromiseKit自己定义了一个block的结构体:
struct PMKBlockLiteral {
void *isa;
int flags;
int reserved;
void (*invoke)(void *, ...);
struct block_descriptor {
unsigned long int reserved; // NULL
unsigned long int size; // sizeof(struct Block_literal_1)
void (*copy_helper)(void *dst, void *src); // IFF (1<<25)
void (*dispose_helper)(void *src); // IFF (1<<25)
const char *signature; // IFF (1<<30)
} *descriptor;
};
熟悉block的同学都知道,flags按照bit位保存了一些block的附加信息,在 1<<30的这个bit可以找到是否有类型签名signature,剩下的就是通过flags移动指针,找到signature所在的内存空间了。找到了signature,也就获取到了参数个数与函数返回值这些信息。函数返回值的类型是经过编码的,具体的对照表可以参考官方文档
id pmk_safely_call_block(id frock, id result) {
NSMethodSignature *sig = NSMethodSignatureForBlock(frock);
const NSUInteger nargs = sig.numberOfArguments;
const char rtype = sig.methodReturnType[0];
type (^block)(id, id, id) = frock;
return [result class] == [PMKArray class]
? block(result[0], result[1], result[2])
: block(result, nil, nil);
}
有了函数签名,就能知道block的信息了。上面只截取了部分代码,简单来说,PromiseKit 通过动态的获取block的参数个数与返回类型来决定block的调用。一般来说, fullfill(id) 在调用的时候最多只支持传递一个参数,在必要的时候,PromiseKit把这些参数放在一个数组里面,这个数组就是 PMKArray ,当检测到这个参数是一个数组的时候,就依次取出数组内的元素作为参数传递。
从而支持了多个参数的传递。
##总结
至此, 对PromiseKit的一些解释也就结束了,PromiseKit有OC的1.0版本,也有支持了swift的3.0版本。如果你非常享受这样的书写方式,可以接入很多扩展的版本,可以写出看起来优雅又舒服的代码,比如 NSURLSession :
URLSession.GET("http://example.com").asDictionary().then { json in
}.catch { error in
//…
}
还有很多的扩展与关键字的支持,这里都不再展开。
而对于我来说,Promise设计模式能够解决我对散落在各处的代理模式产生的代码的烦恼,也让我避免了跳进回调陷阱,就值得总结了。
FROM:iOS 中的 Promise 设计模式
IOS中堆和栈的区别
- 管理方式:
对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制,容易产生memory leak。 2. 申请大小: 栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。 堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。 3. 碎片问题:
对于堆来讲,频繁的new/delete势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存块从栈中间弹出 分配方式:
堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。 4. 分配效率:
栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是C/C++函数库提供的,它的机制是很复杂的。
以下转自:iOS中的堆(heap)和栈(stack)的理解
操作系统iOS 中应用程序使用的计算机内存不是统一分配空间,运行代码使用的空间在三个不同的内存区域,分成三个段:“text segment “,“stack segment ”,“heap segment ”。
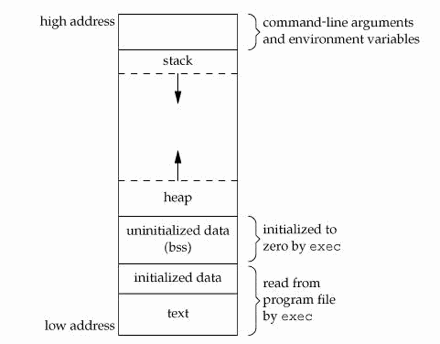
段“text segment ”是应用程序运行时应用程序代码存在的内存段。每一个指令,每一个单个函数、过程、方法和执行代码都存在这个内存段中直到应用程序退出。一般情况下,你不会真的不得不知道这个段的任何事情。
当应用开始以后,函数main() 被调用,一些空间分配在”stack” 中。这是为应用分配的另一个段的内存空间,这是为了函数变量存储需要而分配的内存。每一次在应用中调用一个函数,“stack ”的一部分会被分配在”stack” 中,称之为”frame” 。新函数的本地变量分配在这里。
正如名称所示,“stack ”是后进先出(LIFO )结构。当函数调用其他的函数时,“stack frame ”会被创建;当其他函数退出后,这个“frame ”会自动被破坏。
“heap” 段也称为”data” 段,提供一个保存中介贯穿函数的执行过程,全局和静态变量保存在“heap ”中,直到应用退出。
为了访问你创建在heap 中的数据,你最少要求有一个保存在stack 中的指针,因为你的CPU 通过stack 中的指针访问heap 中的数据。
你可以认为stack 中的一个指针仅仅是一个整型变量,保存了heap 中特定内存地址的数据。实际上,它有一点点复杂,但这是它的基本结构。
简而言之,操作系统使用stack 段中的指针值访问heap 段中的对象。如果stack 对象的指针没有了,则heap 中的对象就不能访问。这也是内存泄露的原因。
在iOS 操作系统的stack 段和heap 段中,你都可以创建数据对象。
stack 对象的优点主要有两点,一是创建速度快,二是管理简单,它有严格的生命周期。stack 对象的缺点是它不灵活。创建时长度是多大就一直是多大,创建时是哪个函数创建的,它的owner 就一直是它。不像heap 对象那样有多个owner ,其实多个owner 等同于引用计数。只有heap 对象才是采用“引用计数”方法管理它。
stack 对象的创建
只要栈的剩余空间大于stack 对象申请创建的空间,操作系统就会为程序提供这段内存空间,否则将报异常提示栈溢出。
heap 对象的创建
操作系统对于内存heap 段是采用链表进行管理的。操作系统有一个记录空闲内存地址的链表,当收到程序的申请时,会遍历链表,寻找第一个空间大于所申请的heap 节点,然后将该节点从空闲节点链表中删除,并将该节点的空间分配给程序。
例如:
NSString 的对象就是stack 中的对象,NSMutableString 的对象就是heap 中的对象。前者创建时分配的内存长度固定且不可修改;后者是分配内存长度是可变的,可有多个owner, 适用于计数管理内存管理模式。
两类对象的创建方法也不同,前者直接创建“NSString * str1=@"welcome"; “,而后者需要先分配再初始化“ NSMutableString * mstr1=[[NSMutableString alloc] initWithString:@"welcome"]; ”。
再补充一点,这里说的是操作系统的堆和栈。
在我们学习“数据结构”时,接触到的堆和栈的概念和这个操作系统中的堆和栈不是一回事的。
操作系统的堆和栈是指对内存进行操作和管理的一些方式。
“数据结构“的堆实际上指的就是(满足堆性质的)优先Queue 的一种数据结构,第1 个元素有最高的优先权;栈实际上就是满足先进后出的性质的数据或数据结构。
Copyright © 2015 Powered by MWeb, 豫ICP备09002885号-5