Python并发工具
转载于:http://mingxinglai.com/cn/2016/09/python-concurrent/
相信每一个接触Python并发的同学,刚开始都会有一段困惑时间:Python的并发看起来杂乱无章. 大家使用最多的是threading,但是,Python中由于GIL的存在,又没有实现真正的并发.因此, 在寻求其他并发工具的时候,Python往往由于资料太多,而大家又没有系统性的学习并发,导致 丈二的和尚摸不着头脑.
API Star:一个 Python 3 的 API 框架
为了在 Python 中快速构建 API,我主要依赖于 Flask。最近我遇到了一个名为 “API Star” 的基于 Python 3 的新 API 框架。由于几个原因,我对它很感兴趣。首先,该框架包含 Python 新特点,如类型提示和 asyncio。而且它再进一步为开发人员提供了很棒的开发体验。我们很快就会讲到这些功能,但在我们开始之前,我首先要感谢 Tom Christie,感谢他为 Django REST Framework 和 API Star 所做的所有工作。
现在说回 API Star —— 我感觉这个框架很有成效。我可以选择基于 asyncio 编写异步代码,或者可以选择传统后端方式就像 WSGI 那样。它配备了一个命令行工具 —— apistar 来帮助我们更快地完成工作。它支持 Django ORM 和 SQLAlchemy,这是可选的。它有一个出色的类型系统,使我们能够定义输入和输出的约束,API Star 可以自动生成 API 的模式(包括文档),提供验证和序列化功能等等。虽然 API Star 专注于构建 API,但你也可以非常轻松地在其上构建 Web 应用程序。在我们自己构建一些东西之前,所有这些可能都没有意义的。
##开始
我们将从安装 API Star 开始。为此实验创建一个虚拟环境是一个好主意。如果你不知道如何创建一个虚拟环境,不要担心,继续往下看。
pip install apistar
(译注:上面的命令是在 Python 3 虚拟环境下使用的)
如果你没有使用虚拟环境或者你的 Python 3 的 pip 名为 pip3,那么使用 pip3 install apistar 代替。
一旦我们安装了这个包,我们就应该可以使用 apistar 命令行工具了。我们可以用它创建一个新项目,让我们在当前目录中创建一个新项目。
apistar new .
现在我们应该创建两个文件:app.py,它包含主应用程序,然后是 test.py,它用于测试。让我们来看看 app.py 文件:
from apistar import Include, Route
from apistar.frameworks.wsgi import WSGIApp as App
from apistar.handlers import docs_urls, static_urls
def welcome(name=None):
if name is None:
return {'message': 'Welcome to API Star!'}
return {'message': 'Welcome to API Star, %s!' % name}
routes = [
Route('/', 'GET', welcome),
Include('/docs', docs_urls),
Include('/static', static_urls)
]
app = App(routes=routes)
if __name__ == '__main__':
app.main()
在我们深入研究代码之前,让我们运行应用程序并查看它是否正常工作。我们在浏览器中输入 http://127.0.0.1:8080/,我们将得到以下响应:
{"message": "Welcome to API Star!"}
如果我们输入:http://127.0.0.1:8080/?name=masnun
{"message": "Welcome to API Star, masnun!"}
同样的,输入 http://127.0.0.1:8080/docs/,我们将看到自动生成的 API 文档。
现在让我们来看看代码。我们有一个 welcome 函数,它接收一个名为 name 的参数,其默认值为 None。API Star 是一个智能的 API 框架。它将尝试在 url 路径或者查询字符串中找到 name 键并将其传递给我们的函数,它还基于其生成 API 文档。这真是太好了,不是吗?
然后,我们创建一个 Route 和 Include 实例的列表,并将列表传递给 App 实例。Route 对象用于定义用户自定义路由。顾名思义,Include 包含了在给定的路径下的其它 url 路径。
##路由
路由很简单。当构造 App 实例时,我们需要传递一个列表作为 routes 参数,这个列表应该有我们刚才看到的 Route 或 Include 对象组成。对于 Route,我们传递一个 url 路径,http 方法和可调用的请求处理程序(函数或者其他)。对于 Include 实例,我们传递一个 url 路径和一个 Routes 实例列表。
##路径参数
我们可以在花括号内添加一个名称来声明 url 路径参数。例如 /user/{user_id} 定义了一个 url,其中 user_id 是路径参数,或者说是一个将被注入到处理函数(实际上是可调用的)中的变量。这有一个简单的例子:
from apistar import Route
from apistar.frameworks.wsgi import WSGIApp as App
def user_profile(user_id: int):
return {'message': 'Your profile id is: {}'.format(user_id)}
routes = [
Route('/user/{user_id}', 'GET', user_profile),
]
app = App(routes=routes)
if __name__ == '__main__':
app.main()
如果我们访问 http://127.0.0.1:8080/user/23,我们将得到以下响应:
{"message": "Your profile id is: 23"}
但如果我们尝试访问 http://127.0.0.1:8080/user/some_string,它将无法匹配。因为我们定义了 user_profile 函数,且为 user_id 参数添加了一个类型提示。如果它不是整数,则路径不匹配。但是如果我们继续删除类型提示,只使用 user_profile(user_id),它将匹配此 url。这也展示了 API Star 的智能之处和利用类型和好处。
##包含/分组路由
有时候将某些 url 组合在一起是有意义的。假设我们有一个处理用户相关功能的 user 模块,将所有与用户相关的 url 分组在 /user 路径下可能会更好。例如 /user/new、/user/1、/user/1/update 等等。我们可以轻松地在单独的模块或包中创建我们的处理程序和路由,然后将它们包含在我们自己的路由中。
让我们创建一个名为 user 的新模块,文件名为 user.py。我们将以下代码放入这个文件:
from apistar import Route
def user_new():
return {"message": "Create a new user"}
def user_update(user_id: int):
return {"message": "Update user #{}".format(user_id)}
def user_profile(user_id: int):
return {"message": "User Profile for: {}".format(user_id)}
user_routes = [
Route("/new", "GET", user_new),
Route("/{user_id}/update", "GET", user_update),
Route("/{user_id}/profile", "GET", user_profile),
]
现在我们可以从 app 主文件中导入 user_routes,并像这样使用它:
from apistar import Include
from apistar.frameworks.wsgi import WSGIApp as App
from user import user_routes
routes = [
Include("/user", user_routes)
]
app = App(routes=routes)
if __name__ == '__main__':
app.main()
现在 /user/new 将委托给 user_new 函数。
访问查询字符串/查询参数
查询参数中传递的任何参数都可以直接注入到处理函数中。比如 url /call?phone=1234,处理函数可以定义一个 phone 参数,它将从查询字符串/查询参数中接收值。如果 url 查询字符串不包含 phone 的值,那么它将得到 None。我们还可以为参数设置一个默认值,如下所示:
def welcome(name=None):
if name is None:
return {'message': 'Welcome to API Star!'}
return {'message': 'Welcome to API Star, %s!' % name}
在上面的例子中,我们为 name 设置了一个默认值 None。
注入对象
通过给一个请求程序添加类型提示,我们可以将不同的对象注入到视图中。注入请求相关的对象有助于处理程序直接从内部访问它们。API Star 内置的 http 包中有几个内置对象。我们也可以使用它的类型系统来创建我们自己的自定义对象并将它们注入到我们的函数中。API Star 还根据指定的约束进行数据验证。
让我们定义自己的 User 类型,并将其注入到我们的请求处理程序中:
from apistar import Include, Route
from apistar.frameworks.wsgi import WSGIApp as App
from apistar import typesystem
class User(typesystem.Object):
properties = {
'name': typesystem.string(max_length=100),
'email': typesystem.string(max_length=100),
'age': typesystem.integer(maximum=100, minimum=18)
}
required = ["name", "age", "email"]
def new_user(user: User):
return user
routes = [
Route('/', 'POST', new_user),
]
app = App(routes=routes)
if __name__ == '__main__':
app.main()
现在如果我们发送这样的请求:
curl -X POST \
http://127.0.0.1:8080/ \
-H 'Cache-Control: no-cache' \
-H 'Content-Type: application/json' \
-d '{"name": "masnun", "email": "masnun@gmail.com", "age": 12}'
猜猜发生了什么?我们得到一个错误,说年龄必须等于或大于 18。类型系允许我们进行智能数据验证。如果我们启用了 docs url,我们还将自动记录这些参数。
##发送响应
如果你已经注意到,到目前为止,我们只可以传递一个字典,它将被转换为 JSON 并作为默认返回。但是,我们可以使用 apistar 中的 Response 类来设置状态码和其它任意响应头。这有一个简单的例子:
from apistar import Route, Response
from apistar.frameworks.wsgi import WSGIApp as App
def hello():
return Response(
content="Hello".encode("utf-8"),
status=200,
headers={"X-API-Framework": "API Star"},
content_type="text/plain"
)
routes = [
Route('/', 'GET', hello),
]
app = App(routes=routes)
if __name__ == '__main__':
app.main()
它应该返回纯文本响应和一个自定义标响应头。请注意,content 应该是字节,而不是字符串。这就是我编码它的原因。
##继续
我刚刚介绍了 API Star 的一些特性,API Star 中还有许多非常酷的东西,我建议通过 Github Readme 文件来了解这个优秀框架所提供的不同功能的更多信息。我还将尝试在未来几天内介绍关于 API Star 的更多简短的,集中的教程。
via: http://polyglot.ninja/api-star-python-3-api-framework/
作者:MASNUN 译者:MjSeven 校对:wxy
Pyhton3一则下载代码
from urllib.request import urlretrieve
import os
def download(url, savepath='./'):
"""
download file from internet
:param url: path to download from
:param savepath: path to save files
:return: None
"""
def reporthook(a, b, c):
"""
显示下载进度
:param a: 已经下载的数据块
:param b: 数据块的大小
:param c: 远程文件大小
:return: None
"""
print("\rdownloading: %5.1f%%" % (a * b * 100.0 / c), end="")
filename = os.path.basename(url)
# 判断文件是否存在,如果不存在则下载
if not os.path.isfile(os.path.join(savepath, filename)):
print('Downloading data from %s' % url)
urlretrieve(url, os.path.join(savepath, filename), reporthook=reporthook)
print('\nDownload finished!')
else:
print('File already exsits!')
# 获取文件大小
filesize = os.path.getsize(os.path.join(savepath, filename))
# 文件大小默认以Bytes计, 转换为Mb
print('File size = %.2f Mb' % (filesize/1024/1024))
if name == 'main':
# 以下载cifar-10数据集为例
url = "https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz"
download(url, savepath='./')
Python中关于“warning: Debugger speedups using cython not found”问题的解决
问题描述:Cython加速调试没有打开。Cython是Python的一个扩展模块工具,采用Python和C语言混合编成,用于加速Python计算速度。
解决方法:
- 打开终端:找到“Pycharm/pycharm-community-2016.2.2/helpers/pydev”完整路径,然后cd到那里,比如我的是:“cd madd/soft/Pycharm/pycharm-community-2016.2.2/helpers/pydev”;
- 输入:“python setup_cython.py build_ext --inplace”,回车;再次运行程序,发现warning已经没有了。
参考:https://blog.jetbrains.com/pycharm/2016/02/faster-debugger-in-pycharm-5-1/
Scrapy爬虫使用
From:https://www.cnblogs.com/wanghzh/p/5824181.html
Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
Scratch,是抓取的意思,这个Python的爬虫框架叫Scrapy,大概也是这个意思吧,就叫它:小刮刮吧。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下:

Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
##基本使用
-
创建项目
运行命令:scrapy startproject p1(your_project_name) -
自动创建目录的结果:
文件说明:
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
- 编写爬虫
在spiders目录中新建 xiaohuar_spider.py 文件
示例代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import scrapy
class XiaoHuarSpider(scrapy.spiders.Spider):
name = "xiaohuar"
allowed_domains = ["xiaohuar.com"]
start_urls = [
"http://www.xiaohuar.com/hua/",
]
def parse(self, response):
# print(response, type(response))
# from scrapy.http.response.html import HtmlResponse
# print(response.body_as_unicode())
current_url = response.url #爬取时请求的url
body = response.body #返回的html
unicode_body = response.body_as_unicode()#返回的html unicode编码
备注:
1.爬虫文件需要定义一个类,并继承scrapy.spiders.Spider
2.必须定义name,即爬虫名,如果没有name,会报错。因为源码中是这样定义的:
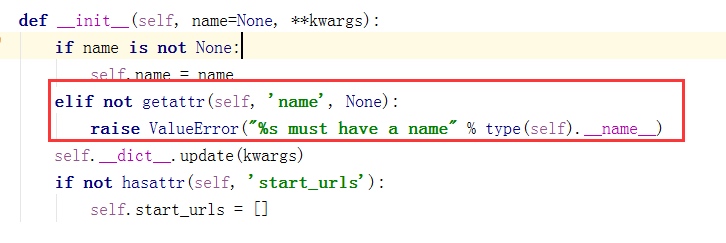
3.编写函数parse,这里需要注意的是,该函数名不能改变,因为Scrapy源码中默认callback函数的函数名就是parse;
4.定义需要爬取的url,放在列表中,因为可以爬取多个url,Scrapy源码是一个For循环,从上到下爬取这些url,使用生成器迭代将url发送给下载器下载url的html。源码截图:


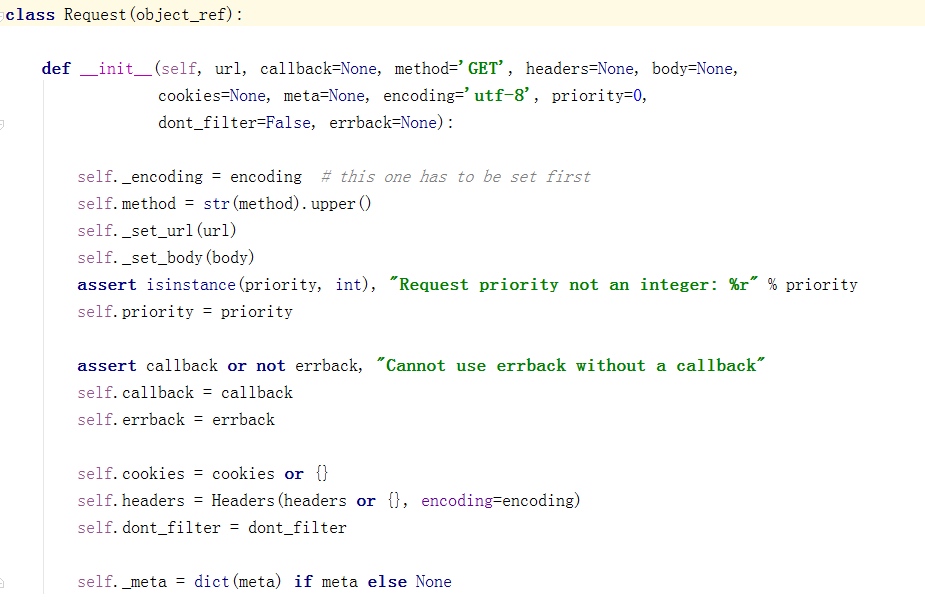
4、运行
进入p1目录,运行命令
scrapy crawl xiaohau --nolog
格式:scrapy crawl+爬虫名 --nolog即不显示日志
5.scrapy查询语法:
当我们爬取大量的网页,如果自己写正则匹配,会很麻烦,也很浪费时间,令人欣慰的是,scrapy内部支持更简单的查询语法,帮助我们去html中查询我们需要的标签和标签内容以及标签属性。下面逐一进行介绍:
- 查询子子孙孙中的某个标签(以div标签为例)://div
- 查询儿子中的某个标签(以div标签为例):/div
- 查询标签中带有某个class属性的标签://div[@class='c1']即子子孙孙中标签是div且class=‘c1’的标签
- 查询标签中带有某个class=‘c1’并且自定义属性name=‘alex’的标签://div[@class='c1'][@name='alex']
- 查询某个标签的文本内容://div/span/text() 即查询子子孙孙中div下面的span标签中的文本内容
- 查询某个属性的值(例如查询a标签的href属性)://a/@href
示例代码
def parse(self, response):
# 分析页面
# 找到页面中符合规则的内容(校花图片),保存
# 找到所有的a标签,再访问其他a标签,一层一层的搞下去
hxs = HtmlXPathSelector(response)#创建查询对象
# 如果url是 http://www.xiaohuar.com/list-1-\d+.html
if re.match('http://www.xiaohuar.com/list-1-\d+.html', response.url): #如果url能够匹配到需要爬取的url,即本站url
items = hxs.select('//div[@class="item_list infinite_scroll"]/div') #select中填写查询目标,按scrapy查询语法书写
for i in range(len(items)):
src = hxs.select('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/a/img/@src' % i).extract()#查询所有img标签的src属性,即获取校花图片地址
name = hxs.select('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/span/text()' % i).extract() #获取span的文本内容,即校花姓名
school = hxs.select('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/div[@class="btns"]/a/text()' % i).extract() #校花学校
if src:
ab_src = "http://www.xiaohuar.com" + src[0]#相对路径拼接
file_name = "%s_%s.jpg" % (school[0].encode('utf-8'), name[0].encode('utf-8')) #文件名,因为python27默认编码格式是unicode编码,因此我们需要编码成utf-8
file_path = os.path.join("/Users/wupeiqi/PycharmProjects/beauty/pic", file_name)
urllib.urlretrieve(ab_src, file_path)
注:urllib.urlretrieve(ab_src, file_path) ,接收文件路径和需要保存的路径,会自动去文件路径下载并保存到我们指定的本地路径。
5.递归爬取网页
上述代码仅仅实现了一个url的爬取,如果该url的爬取的内容中包含了其他url,而我们也想对其进行爬取,那么如何实现递归爬取网页呢?
示例代码:
# 获取所有的url,继续访问,并在其中寻找相同的url
all_urls = hxs.select('//a/@href').extract()
for url in all_urls:
if url.startswith('http://www.xiaohuar.com/list-1-'):
yield Request(url, callback=self.parse)
即通过yield生成器向每一个url发送request请求,并执行返回函数parse,从而递归获取校花图片和校花姓名学校等信息。
注:可以修改settings.py 中的配置文件,以此来指定“递归”的层数,如: DEPTH_LIMIT = 1
6.scrapy查询语法中的正则:
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
html = """<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<li class="item-"><a href="link.html">first item</a></li>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
</body>
</html>
"""
response = HtmlResponse(url='http://example.com', body=html,encoding='utf-8')
ret = Selector(response=response).xpath('//li[re:test(@class, "item-\d*")]//@href').extract()
print(ret)
语法规则:Selector(response=response查询对象).xpath('//li[re:test(@class, "item-\d*")]//@href').extract(),即根据re正则匹配,test即匹配,属性名是class,匹配的正则表达式是"item-\d*",然后获取该标签的href属性。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import scrapy
import hashlib
from tutorial.items import JinLuoSiItem
from scrapy.http import Request
from scrapy.selector import HtmlXPathSelector
class JinLuoSiSpider(scrapy.spiders.Spider):
count = 0
url_set = set()
name = "jluosi"
domain = 'http://www.jluosi.com'
allowed_domains = ["jluosi.com"]
start_urls = [
"http://www.jluosi.com:80/ec/goodsDetail.action?jls=QjRDNEIzMzAzOEZFNEE3NQ==",
]
def parse(self, response):
md5_obj = hashlib.md5()
md5_obj.update(response.url)
md5_url = md5_obj.hexdigest()
if md5_url in JinLuoSiSpider.url_set:
pass
else:
JinLuoSiSpider.url_set.add(md5_url)
hxs = HtmlXPathSelector(response)
if response.url.startswith('http://www.jluosi.com:80/ec/goodsDetail.action'):
item = JinLuoSiItem()
item['company'] = hxs.select('//div[@class="ShopAddress"]/ul/li[1]/text()').extract()
item['link'] = hxs.select('//div[@class="ShopAddress"]/ul/li[2]/text()').extract()
item['qq'] = hxs.select('//div[@class="ShopAddress"]//a/@href').re('.*uin=(?P<qq>\d*)&')
item['address'] = hxs.select('//div[@class="ShopAddress"]/ul/li[4]/text()').extract()
item['title'] = hxs.select('//h1[@class="goodsDetail_goodsName"]/text()').extract()
item['unit'] = hxs.select('//table[@class="R_WebDetail_content_tab"]//tr[1]//td[3]/text()').extract()
product_list = []
product_tr = hxs.select('//table[@class="R_WebDetail_content_tab"]//tr')
for i in range(2,len(product_tr)):
temp = {
'standard':hxs.select('//table[@class="R_WebDetail_content_tab"]//tr[%d]//td[2]/text()' %i).extract()[0].strip(),
'price':hxs.select('//table[@class="R_WebDetail_content_tab"]//tr[%d]//td[3]/text()' %i).extract()[0].strip(),
}
product_list.append(temp)
item['product_list'] = product_list
yield item
current_page_urls = hxs.select('//a/@href').extract()
for i in range(len(current_page_urls)):
url = current_page_urls[i]
if url.startswith('http://www.jluosi.com'):
url_ab = url
yield Request(url_ab, callback=self.parse)
响应cookie:
def parse(self, response):
from scrapy.http.cookies import CookieJar
cookieJar = CookieJar()
cookieJar.extract_cookies(response, response.request)
print(cookieJar._cookies)
更多选择器规则:http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/selectors.html
7、格式化处理
上述实例只是简单的图片处理,所以在parse方法中直接处理。如果对于想要获取更多的数据(获取页面的价格、商品名称、QQ等),则可以利用Scrapy的items将数据格式化,然后统一交由pipelines来处理。即不同功能用不同文件实现。
items:即用户需要爬取哪些数据,是用来格式化数据,并告诉pipelines哪些数据需要保存。
示例items.py文件:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class JieYiCaiItem(scrapy.Item):
company = scrapy.Field()
title = scrapy.Field()
qq = scrapy.Field()
info = scrapy.Field()
more = scrapy.Field()
即:需要爬取所有url中的公司名,title,qq,基本信息info,更多信息more。
上述定义模板,以后对于从请求的源码中获取的数据同样按照此结构来获取,所以在spider中需要有一下操作:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import scrapy
import hashlib
from beauty.items import JieYiCaiItem
from scrapy.http import Request
from scrapy.selector import HtmlXPathSelector
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class JieYiCaiSpider(scrapy.spiders.Spider):
count = 0
url_set = set()
name = "jieyicai"
domain = 'http://www.jieyicai.com'
allowed_domains = ["jieyicai.com"]
start_urls = [
"http://www.jieyicai.com",
]
rules = [
#下面是符合规则的网址,但是不抓取内容,只是提取该页的链接(这里网址是虚构的,实际使用时请替换)
#Rule(SgmlLinkExtractor(allow=(r'http://test_url/test?page_index=\d+'))),
#下面是符合规则的网址,提取内容,(这里网址是虚构的,实际使用时请替换)
#Rule(LinkExtractor(allow=(r'http://www.jieyicai.com/Product/Detail.aspx?pid=\d+')), callback="parse"),
]
def parse(self, response):
md5_obj = hashlib.md5()
md5_obj.update(response.url)
md5_url = md5_obj.hexdigest()
if md5_url in JieYiCaiSpider.url_set:
pass
else:
JieYiCaiSpider.url_set.add(md5_url)
hxs = HtmlXPathSelector(response)
if response.url.startswith('http://www.jieyicai.com/Product/Detail.aspx'):
item = JieYiCaiItem()
item['company'] = hxs.select('//span[@class="username g-fs-14"]/text()').extract()
item['qq'] = hxs.select('//span[@class="g-left bor1qq"]/a/@href').re('.*uin=(?P<qq>\d*)&')
item['info'] = hxs.select('//div[@class="padd20 bor1 comard"]/text()').extract()
item['more'] = hxs.select('//li[@class="style4"]/a/@href').extract()
item['title'] = hxs.select('//div[@class="g-left prodetail-text"]/h2/text()').extract()
yield item
current_page_urls = hxs.select('//a/@href').extract()
for i in range(len(current_page_urls)):
url = current_page_urls[i]
if url.startswith('/'):
url_ab = JieYiCaiSpider.domain + url
yield Request(url_ab, callback=self.parse)
上述代码中:对url进行md5加密的目的是避免url过长,也方便保存在缓存或数据库中。
此处代码的关键在于:
将获取的数据封装在了Item对象中
yield Item对象 (一旦parse中执行yield Item对象,则自动将该对象交个pipelines的类来处理)
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
from twisted.enterprise import adbapi
import MySQLdb.cursors
import re
mobile_re = re.compile(r'(13[0-9]|15[012356789]|17[678]|18[0-9]|14[57])[0-9]{8}')
phone_re = re.compile(r'(\d+-\d+|\d+)')
class JsonPipeline(object):
def __init__(self):
self.file = open('/Users/wupeiqi/PycharmProjects/beauty/beauty/jieyicai.json', 'wb')
def process_item(self, item, spider):
line = "%s %s\n" % (item['company'][0].encode('utf-8'), item['title'][0].encode('utf-8'))
self.file.write(line)
return item
class DBPipeline(object):
def __init__(self):
self.db_pool = adbapi.ConnectionPool('MySQLdb',
db='DbCenter',
user='root',
passwd='123',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True)
def process_item(self, item, spider):
query = self.db_pool.runInteraction(self._conditional_insert, item)
query.addErrback(self.handle_error)
return item
def _conditional_insert(self, tx, item):
tx.execute("select nid from company where company = %s", (item['company'][0], ))
result = tx.fetchone()
if result:
pass
else:
phone_obj = phone_re.search(item['info'][0].strip())
phone = phone_obj.group() if phone_obj else ' '
mobile_obj = mobile_re.search(item['info'][1].strip())
mobile = mobile_obj.group() if mobile_obj else ' '
values = (
item['company'][0],
item['qq'][0],
phone,
mobile,
item['info'][2].strip(),
item['more'][0])
tx.execute("insert into company(company,qq,phone,mobile,address,more) values(%s,%s,%s,%s,%s,%s)", values)
def handle_error(self, e):
print 'error',e
上述代码中多个类的目的是,可以同时保存在文件和数据库中,保存的优先级可以在配置文件settings中定义。
ITEM_PIPELINES = {
'beauty.pipelines.DBPipeline': 300,
'beauty.pipelines.JsonPipeline': 100,
}
# 每行后面的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。
Copyright © 2015 Powered by MWeb, 豫ICP备09002885号-5